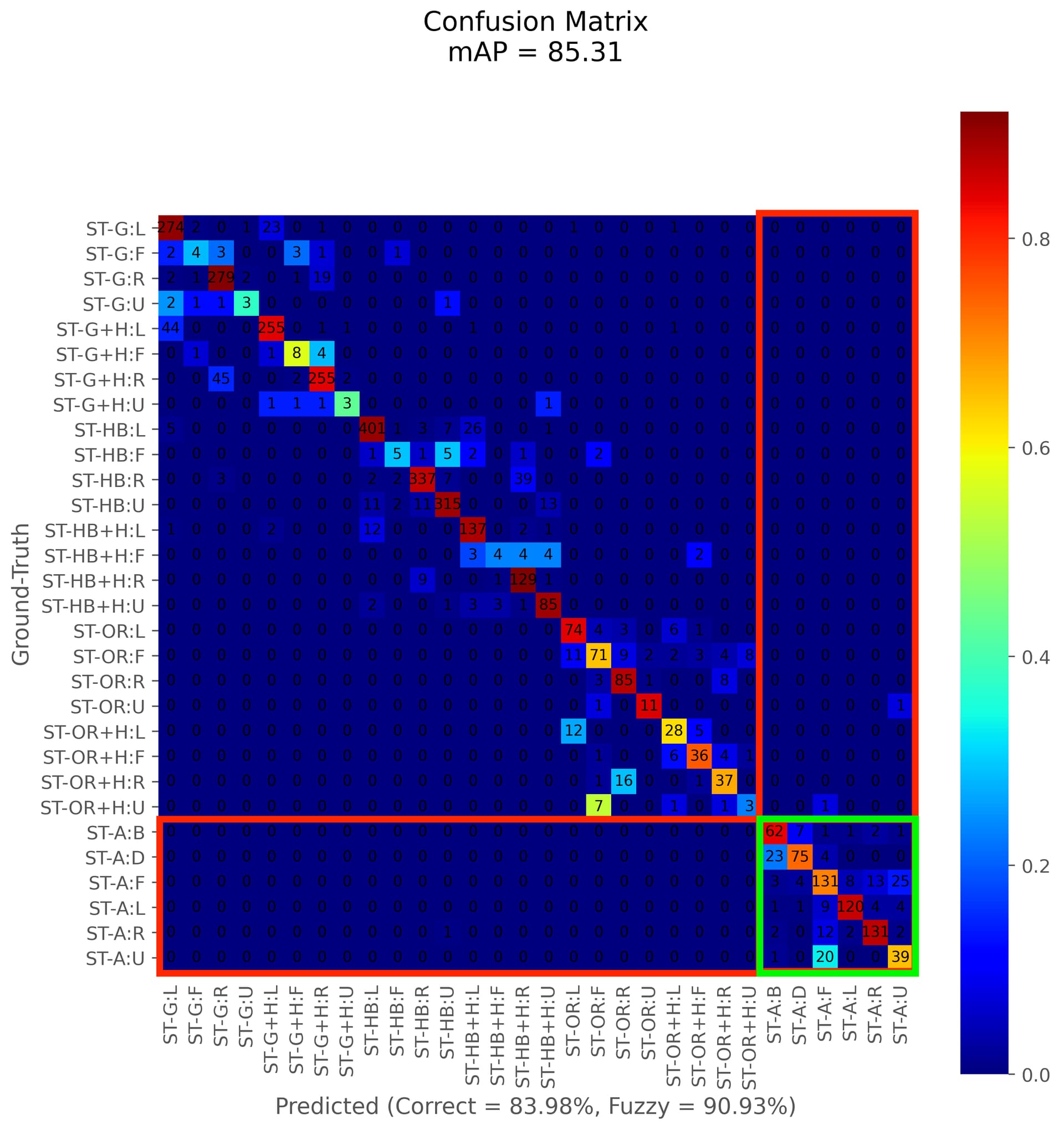
The confusion matrix for the labeler (for all species) shows an overall 84% accuracy at predicting species and viewpoint together. When we restrict the accuracy to species only, the model is 91% accurate at performing species predictions (most of the error is with misclassifying heads and bodies for the same species). Looking at the Asian sea turtle (ST-A) classification performance (green box), we can see how well the system is accurately predicting viewpoints for just that species. Note that the dark blue grid squares in the red boxes are inter-species misclassification with Asian sea turtles, which is very rare.
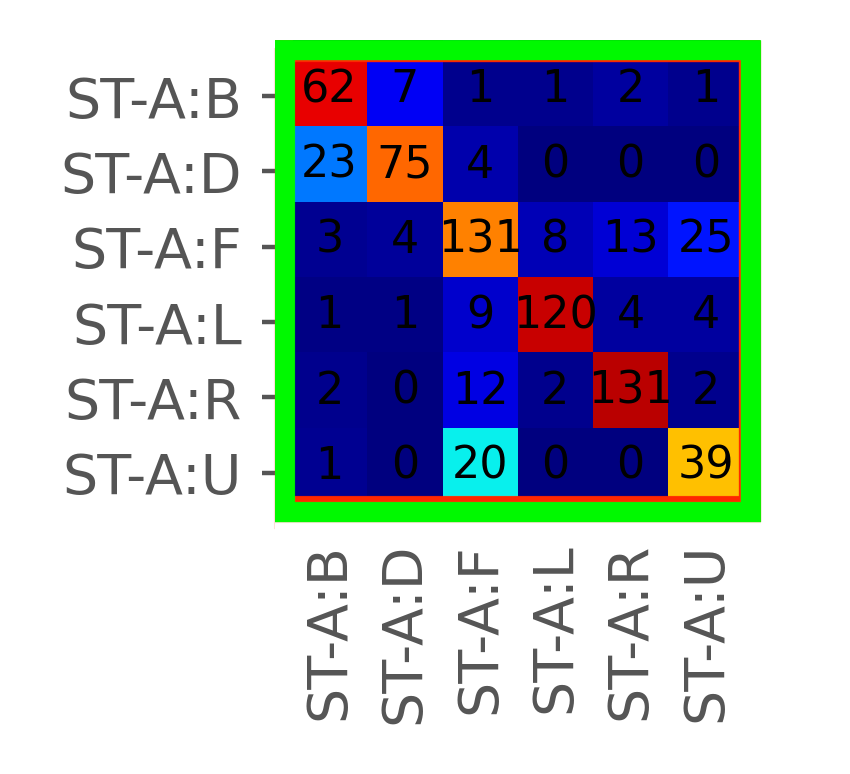
Looking closer at the confusion matrix for just Asian sea turtles, we can see that left and right perform by far the best (dark red, high 90% accuracy). Note that the predicted value is on the x-axis and the ground-truth label is on the y-axis. The model has the most trouble with the Up viewpoint, consistently mislabeling it as Front (and vise-versa). The Down and Back viewpoints also share similar trade-offs with errors. That being said, each viewpoint by itself is still fairly accurate in aggregate, scoring at least 60-70%.
The most straightforward solution to this problem is to gather more training data of these additional viewpoints. The other challenge is that the true viewpoints that are annotated are often too rare to justify adding them as unique classes. The following mapping is used to merge secondary viewpoints into the most likely primary bucket (e.g., merging “frontleft” into “front”).
left -> left
frontleft -> front
front -> front
frontright -> front
right -> right
backright -> back
back -> back
backleft -> back
up -> up
upleft -> left
upfront -> front
upright -> right
upback -> back
down -> down
downleft -> left
downfront -> front
downright -> right
downback -> back
Other than additional data, changing the mapping for the Asian sea turtle species may help to separate the errors between Up-Front and Down-Back by not merging the “upfront” ground-truth label into “front” and the “downback” label into “back”. The challenge to allowing these additional categories is sufficient training data.
Here are a few resources that can help you with the workaround to a bad annotation from detection, which is to manually delete and redraw the annotation: