Thank for fixing our mistake with not assiging Encounter.submitterID and typing the incorrect locationID. We apologize for the inconvience, and really apriciate the help from your team!
Thanks for your patience. Your bulk imports have been assigned to you and their location IDs are now all consistent. Now if you re-start a match, it should show you all of the correct match candidates.
You have a lot of data and large bulk imports, so I don’t recommend you re-run ID until you’re ready to review those matches to prevent overloading the job queues.
Hi Anastasia
Thank you so much for fixing the location IDs.
We’ve been re-running the identification on the 2023 dataset and the results are still only comparing with the 2023 data. We were wondering if this has something to do with the prior data from previous years (2012-2022) not having gone through detection, as we have previously stated.
If the detection is the issue, is there a way in which we can fix the detection being stuck at (0/X) images? We tried to submit the 2021 images for detection to see if it fixed the identification, but it seems to be stuck.
Ah, that’s a possibility. We’re reviewing images that have missed detection in GiraffeSpotter and will ensure those are complete on our end. As soon as I have a status update, I’ll let you know here.
We’ve restarted WBIA and it’s gradually getting through detections that were previously missed.
We’ve also enabled the MiewID algorithm in GiraffeSpotter. It’s been tested on reticulated giraffes, but has not yet been tested on Giraffa giraffa. As you review your matches, let us know if you see improvements in match candidate suggestions with MiewID compared with Hotspotter.
So our 2023 data (our non assigned individual) is still matching to 2023 data, instead of our ‘old data’ (individual assigned data). So we have now sent it all to detection.
We are confused why we suddently have to send our ‘old data’ (individual assigned data) to detection, because last time we asked this, we were told not to send the ‘old’ data til detection and identification.
Sorry for the confusion! I asked @tanyastere about this because it didn’t sound familiar and she said that may have been part of an earlier conversation where your imports were too large and the detections were lagging due to their size.
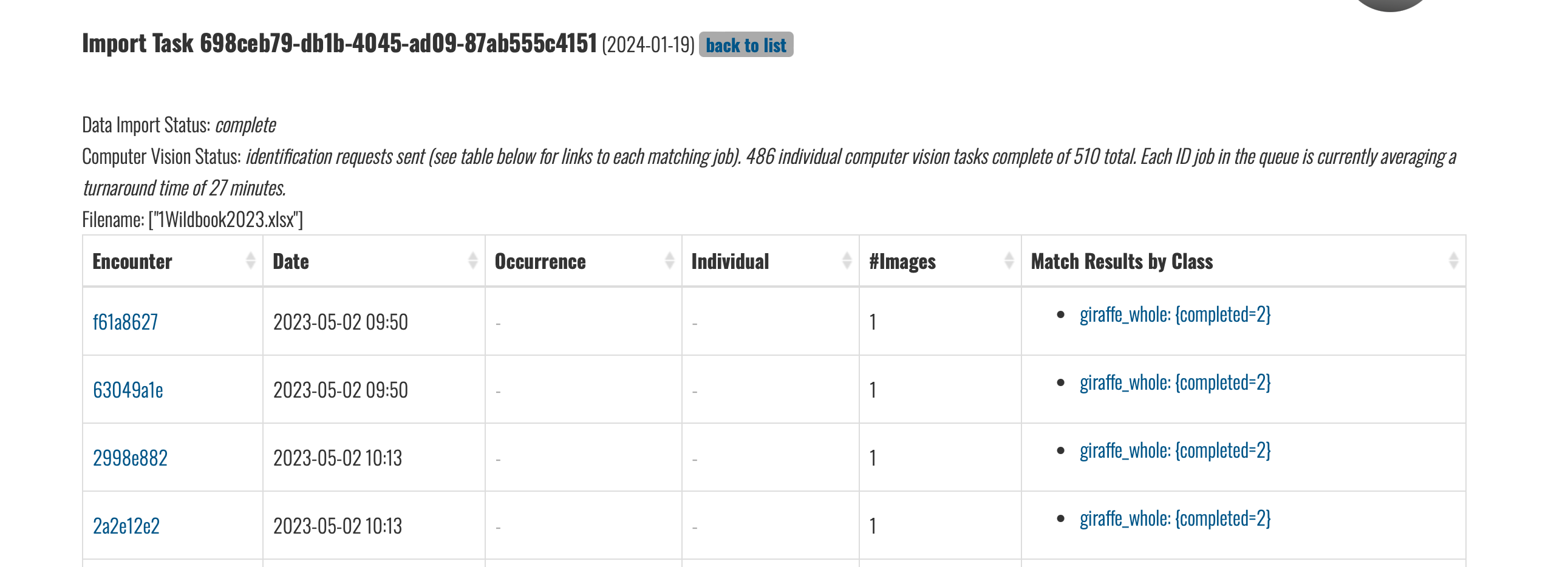
Everything seems to be working after all the old data has been to detection. The only upload that is stuck in detection now is “Wildbook2017.4”. Can you force it through detection from your end? Then we are all set for identification
Again, thank you for all the help throughout the process
Hi Anastasia!
We just recieved our first identification, and we are EXTREMELY impressed! We are over the moon of how well it works. Thank you again so much for your help. Your AI tool is truly an amazing and impressive tool, that works great! We are very pleased with the results.
I’ve manually sent these to detection and they’re now complete and ready for ID.
I looked up the import and saw that several ID jobs had errors. I manually re-sent just the jobs with errors back through ID. The GiraffeSpotter queue is pretty busy today, so give it some time to complete and let me know if you’re still seeing issues.
Great question. The short answer is that scoring varies per algorithm and even within different instances of each algorithm. We’re working on ways to make that more transparent in the match page, but we recommend focusing on just the ranking for now. I cover this a bit in our matching tutorial video. Hotspotter only shows match results with a score higher than 0. For example, if you manually update the list to show you more than 12 matches but there are only 3 candidates with a match score above 0, you’ll still only see 3 results shown.
It looks like it’s already been deleted. This message “Your bulk import may not be ready for viewing yet, or task ID a5807bd7-84d0-4389-9dc7-813aa216561d may be invalid” typically means the import was deleted. I verified by looking at your full list of imports and I did not find Wildbook2017.xlsx in that list.
We started identifying yesterday and experienced that Hotspotter worked better than Miew. Though we would still ike to keep both because Miew is a good extra help.
But the issue is that some run Miew two times instead of Miew and Hotspotter. Fx. this on:
That’s odd. Try starting a new match from the Encounter page. It should show both MiewID and Hotspotter selected as the algorithms to run for the new match.