Amphibian and Reptile Wildbook - Bombina variegata
→ Bulk import: “bf002f55-6fd5-4616-b884-d6cfbc10dad1” from 2022-01-22, 186 Encounters
Unfortunately, the AI does not recognise about 50% of the individuals. The images from 2020 are not tailored to the individuals and the AI was not trained with them, I think that’s where the problem comes from. A similar problem can also be observed with other bulk imports.
Is there a way to make this process more reliable in finding the individuals as well? Or would it be advisable to do the more time-consuming manual annotation for the cases? Since it’s a large amount, I thought I’d better ask.
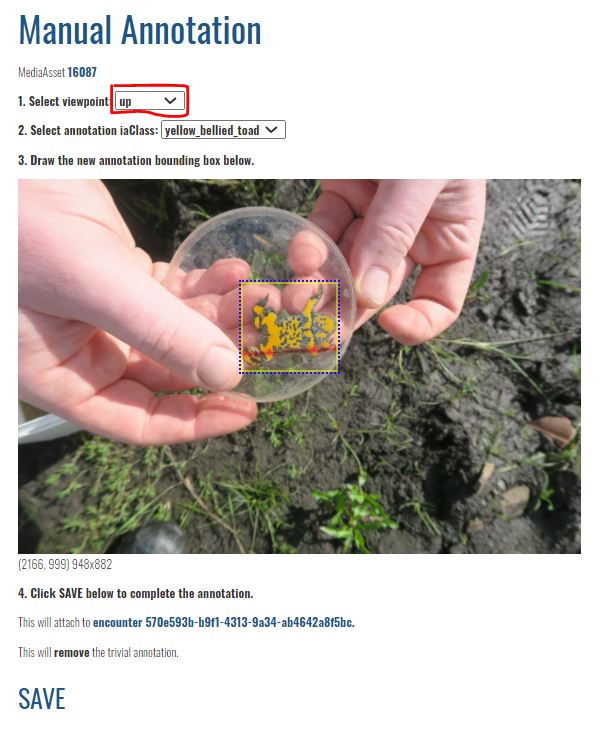
With the manual annotation, I am unsure whether the viewpoint “up” is correct? The other choices are only “left” and “right”.
This is why we ask for as diverse of data upfront as possible. As you note, the AI was not trained on this form of data collection, and it is not finding all of the frogs that can found. The workaround is manual annotation, and without entirely retraining the detector on this new form of data, nothing can be done to improve its performance on data it didn’t have for training.
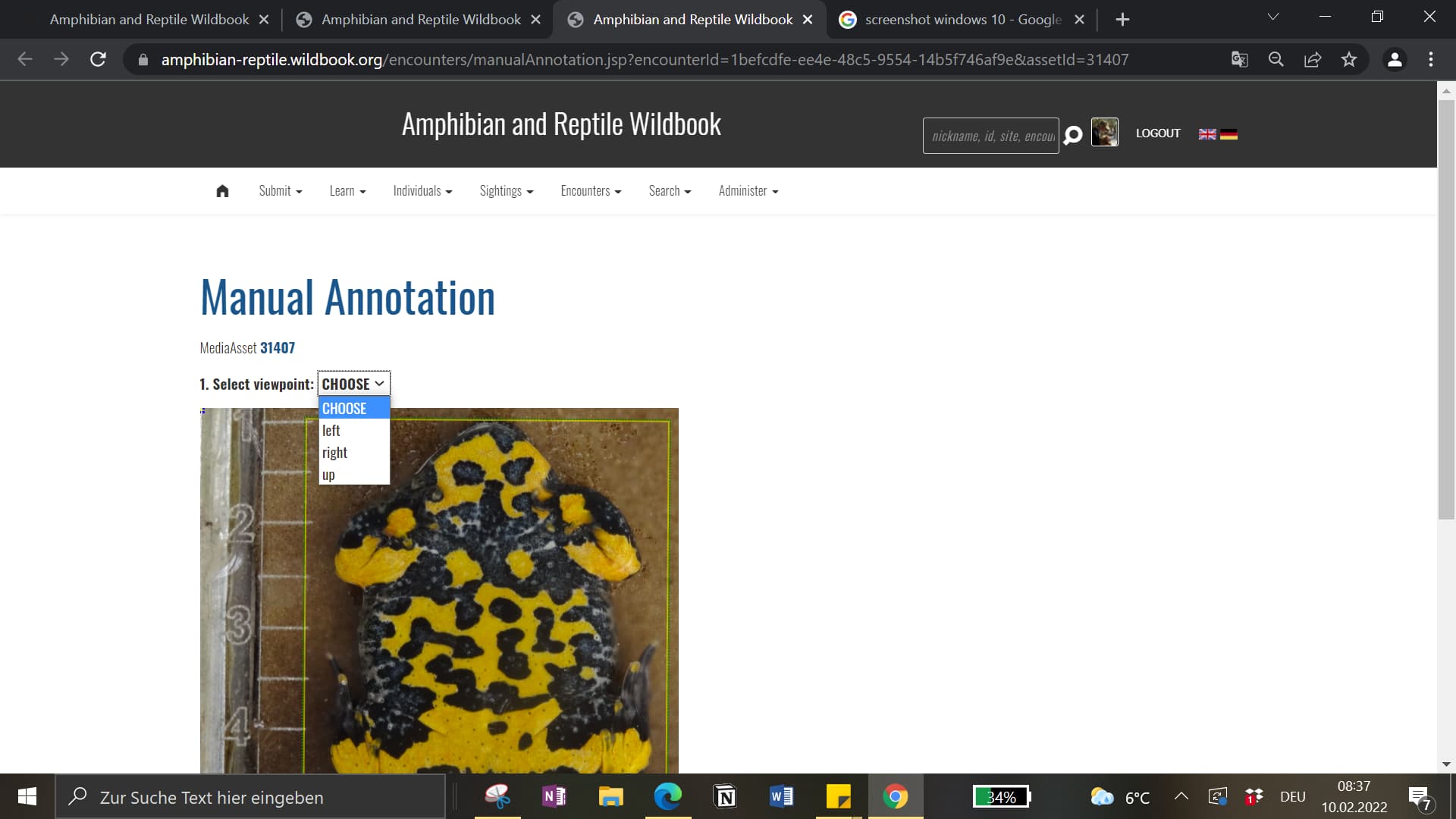
The other question is whether the viewpoint “up” is correct for the manual annotation? The other choices are only “left” and “right”. For reference please have a look at the second photo above.