@JakeBritnell
Apologies for taking three weeks to get back to you soon your post.
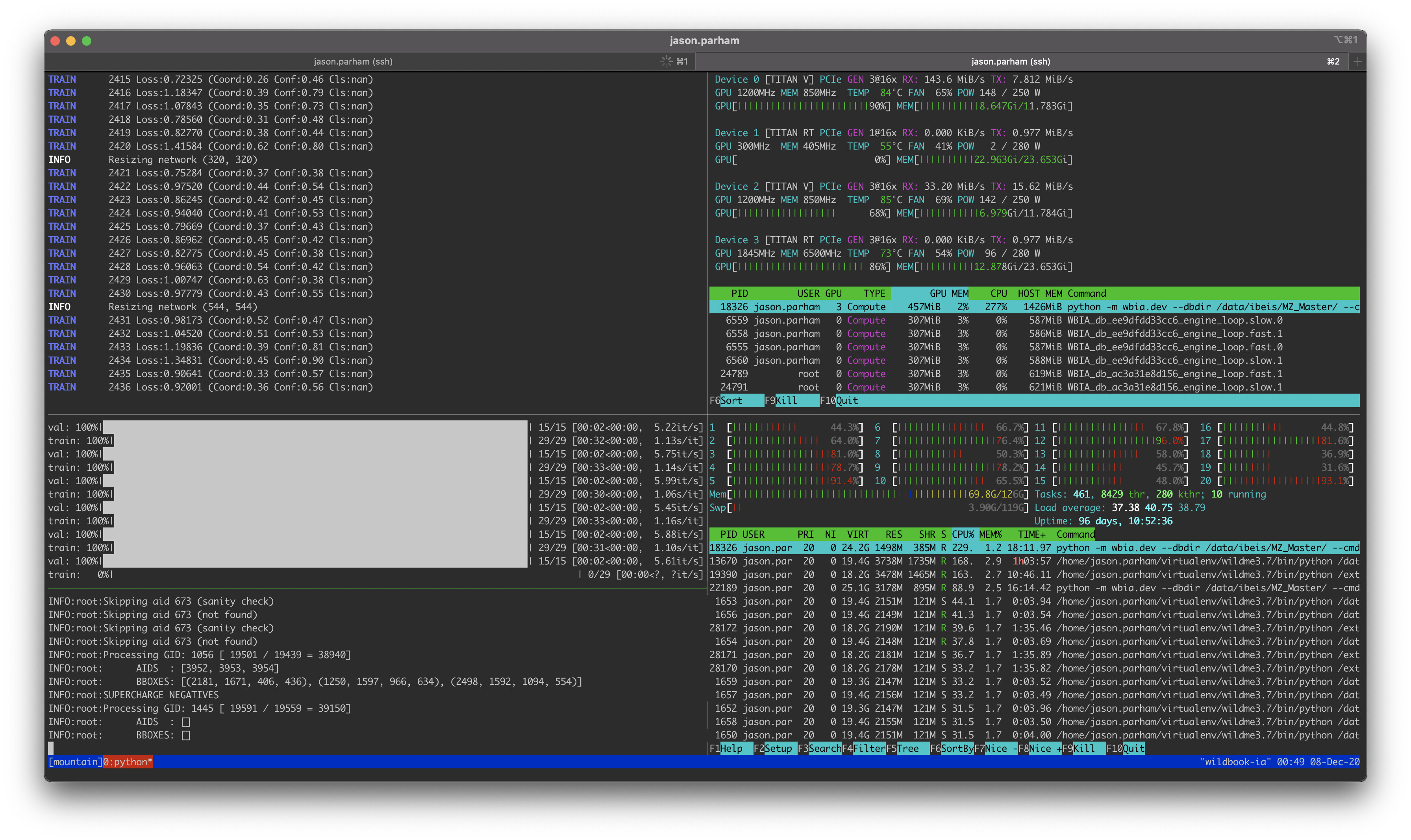
We can confirm that your database has new images – totaling 14,231 – that adds just over 12k to the existing 2,165 we had there before. We were able to successfully run the detection pipeline that we had trained on this new data and automatically created 22,050 annotations for Mountain Zebras (originally there were 4,064 zebra annotations). This represents a greater than 600% increase in the number of annotations that we have available in the dataset for this species. Below are 15 example (randomly selected) detections on images the detector had never seen before.
We also were able to run the labeler model to automatically verify and assign viewpoints to the zebras. This is the breakdown of how many viewpoints the system now contains:
'left' : 8313
'frontleft' : 1625
'front' : 2742
'frontright' : 1868
'right' : 8166
'backright' : 1093
'back' : 1307
'backleft' : 1000
'upfront' : 1
'upright' : 1
As for the decisions, you and your team had compiled a set of just over 17k pairwise review decisions. We trained a random forrest classifier ensemble (VAMP) that can try to automate the decisions going forward. We have balanced the runtime performance of the new VAMP model such that it decides positive, negative, and “cannot tell” decisions with independent thresholds. These thresholds have been selected where the FPR is 1% in held-out test data. The model was deployed to our model CDN in Azure, the source code was updated to support the new ID algorithms for Mountain Zebras, and built into our latest development Docker image for deployment.
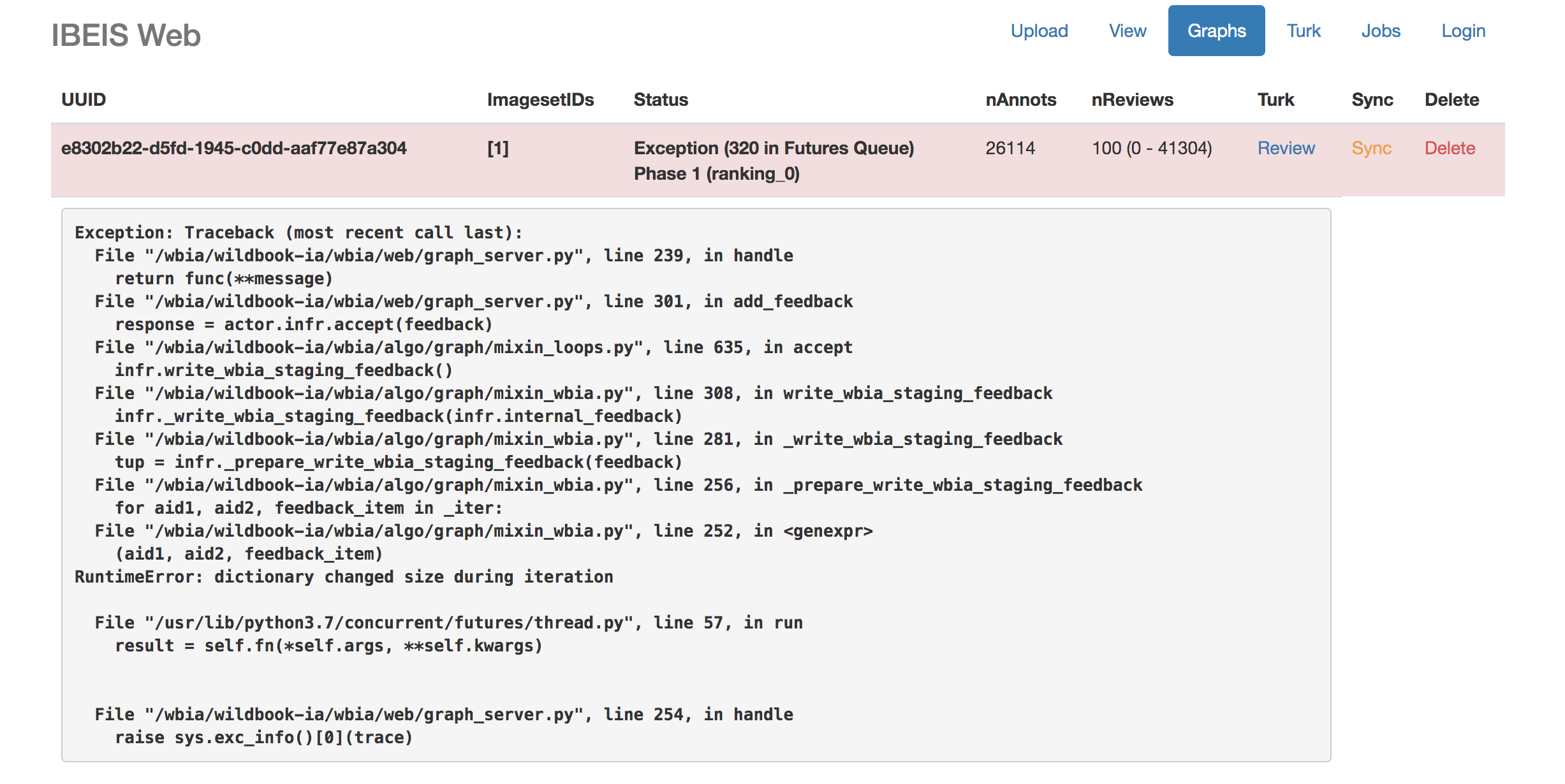
Your database is now running the newest WBIA deployable image and is processing (and caching) the ID results for a “all-vs-all” match using the GraphID algorithm. I will email you a direct (private) link of where these matches are once this initial compute is complete and there are new match candidates to inspect. Expect this link by the end of this week (there is a lot of data to compute).
As for the new dataset, you originally had 4k annotations in your ID graph and it required 17,000 reviews to resolve. The new graph has 26k annotations so the expected number of pairwise reviews is estimated to be around 100k. Note that the automated VAMP decisions will not eliminate the need to do reviews as the 1% error rate will lead to some inconsistencies that will need to be resolved, but we expect the workload on the number of reviews to decrease by at least half. With VAMP enabled this leaves around 50k decisions to do. Luckily, we restart the new graph with the decisions you had made previously, so the estimate for the number of reviews is going to be around 30k for this new graph to be consistent. This estimate will fluctuate based on how identifiable the animals are and how many resightings are in the underlying sightings data. Also, this estimate may fluctuate based on how well VAMP is able to automate the decisions that are presented to it. Also, the level of “consistency” can be configured and, by design, the system should quickly drive the results towards an approximate answer. Lastly, we can reduce this workload by focusing on only left or right viewpoint sightings, which should significantly reduce the amount of reviews and should still give a representative understanding of your population dynamics.
Thanks,
Jason Parham
P.S. If the images fail to load, we migrated the domain for this community website. Please use this link instead: Completed match pair turking of Cape mountain zebra WildBook installment