The Spotting Giant Sea Bass project is looking to bolster our data set of encounters of our target species, giant sea bass, and are considering doing a concerted web scrape. Nothing too fancy, most likely an intern who would search around on social media, California underwater photography websites/blogs, etc., for images not already in our database.
Has anyone done something like this before? If so, how did you approach it? Did it work well? Do you have any advice?
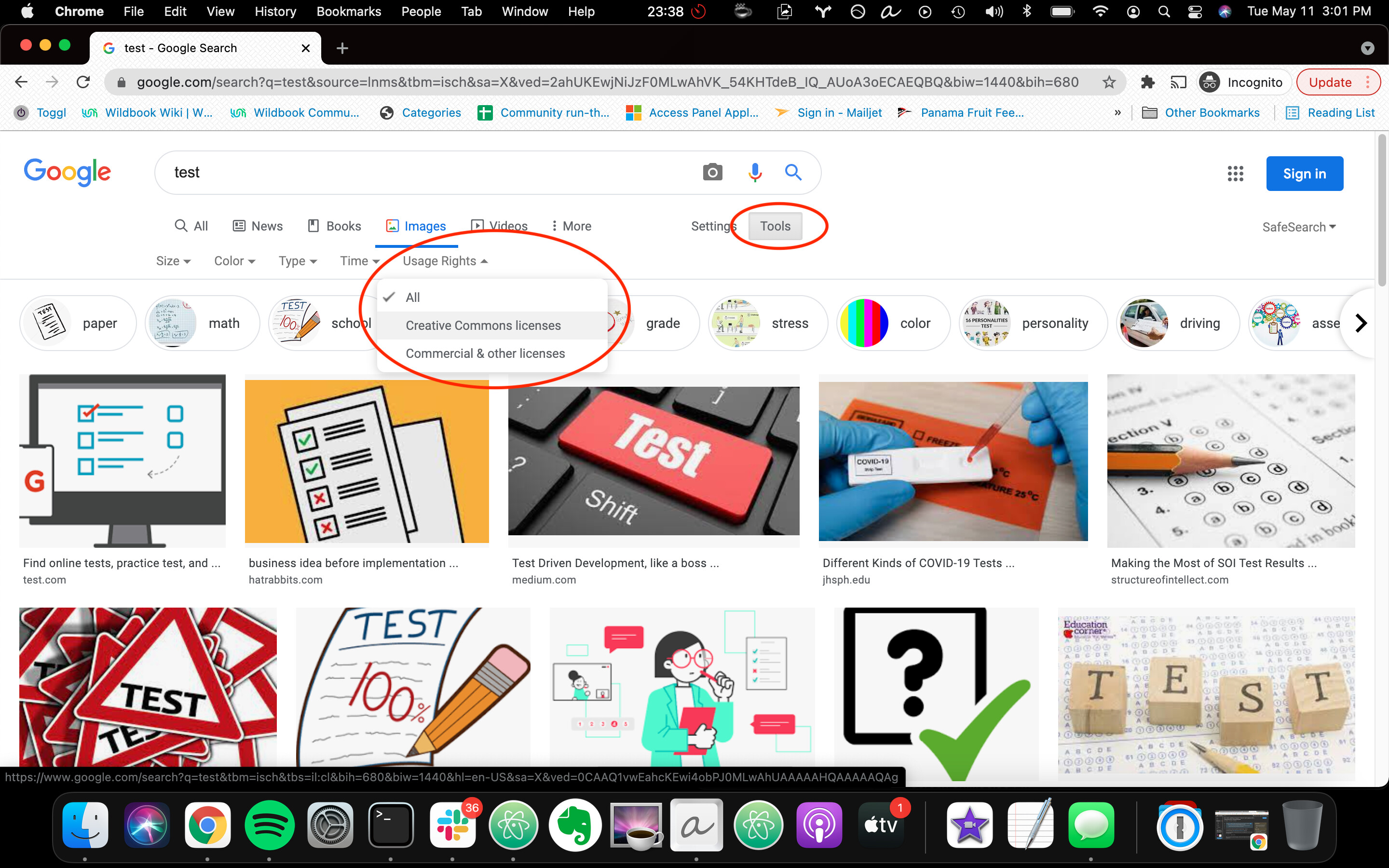
I checked with the team, and really the only recommendation that we have for you is to be careful with the ownership of the images. I know, for instance, that google has a way to limit your search results to certain licensing (see image).
If you find anything useful during your process, by all means please post here for posterity.
Thanks for the suggestion. Totally agree we should be mindful of permissions. Our idea is that we would try to contact the media owner to either 1) ask them to submit it to the website themselves or 2) ask their permission for us to submit it on their behalf. That’s also a good point that we could filter Google images by the different licensing options, too.