In working towards a more functional/streamlined system of making bulk uploads in zebra wildbook, we are continuing to run into a few snags that I wanted to take some time to figure out.
A couple of these are specific instance issues I wanted to draw attention to or requests for clarification regarding best practice when importing/matching etc, but a lot of this post deals with our lingering confusions over what to do with pictures taken of zebras in groups (integrating social relationship data, occurrence vs. encounter fields, etc).
Descriptions for each of the sections are long because I wanted to be as specific as possible.
Thanks for all the help,
Fiona
Bulk import send to identification function and some detection/identification weirdness with Import Task 34264d7f-9058-4321-99d2-1e6a044e39bc:
I have a set of eight pictures of individual zebras (taken on June 11th 2020) that I originally uploaded back before I had administrator permissions to kick off the detection/identification process. The boxes never appeared around the zebras, so later, once I got admin privileges, I deleted the task, uploaded everything again, and set it to go to identification (this is back in December). The process never finished that time either, and none of the zebras got past the “still waiting for detection” label. Meanwhile, Maggie and I have gotten detection to run successfully on other bulk imports. Yesterday, I finally deleted that task, reuploaded, and tried again- except this time only selecting “send to detection” and not “identification”. It worked fine.
It’s possibly that there was just something glitchy with that particular import, but I’m left wondering if there might be an issue with the “send to identification” function. More to the point, I’d like to better understand how sending images directly into the identification process is supposed to work, on both the front and back ends. Once detection is completed, and it runs the matches, are you then able to review the results for each photo before assigning zebras to IDs? Or will it automatically assign them to the match with the highest score? If the program somehow determines that a zebra is an unmatched first encounter, will it generate an automatic alphanumerical ID, and if so, could you change the name after the fact to match an existing naming convention?
Matching with nested location IDs:
I am a little confused about the matching process with zebras sorted into hierarchical locationID categories.
Back in the summer, I remember there being a discussion in which it was recommended that we avoid using tags like Mpala.Central for Encounter.locationID and instead stick to the broader designation Mpala. The reasoning was that Mpala.Central encounters would not be matched against zebras in other Mpala categories and that using a subdivision would constrain the process, when realistically, a zebra could show up again anywhere within the conservancy. I think we were also told or somehow discovered that if a zebra was marked as just Mpala, or if we ran a match against “Mpala” generally, it wouldn’t run against the subcategories and only look at ones with that exact ID, but without further information (Mpala, but not Mpala.North etc), so we have tried to make sure that the pictures we upload have that same location ID.
(this has been mostly with single encounter import and just using the “match results” button, rather than “start another match” and then adding parameters with the checkboxes)
I was wondering if, now, when you run a match against a zebra listed as “Mpala”, if it will still only look at Mpala, or if it will include the zebras that fall into subdivisions of that conservancy, as well. I’d also like to know explicitly whether you can have a zebra labelled as Mpala.Central, and still successfully run the match process against a larger pool.
With bulk import, I’ve noticed that, if you choose to run detection on the pictures in bulk, and then go to match them, you automatically get the dropdown whereby you choose criteria to match against. Why is that? Does it have any implications that I should be aware of? If you check Mpala and all its subcats does the system observe the selection?
Additionally, if you choose to send bulk import images to identification directly, what will happen, in terms of the images they are allowed to match against? Particularly, if there are a mix of location IDs on your spreadsheet, or the location IDs are all within a subcategory of some kind, what will the automatic response of wildbook be, and would it be possible to set it so they are matched against a pool that is above their label in the hierarchy?
What bulk import fields are best for comments?
Frequently our data comes in with little side notes that it would be nice to include. Right now we have Encounter.occurenceRemarks as our column for this in the spreadsheet, but there seem to be a number of different options with a similar function on the wiki- all unconstrained string type fields e.g. Encounter.researcherComments and Occurence.comments. What are the functional distinctions between these, and where do they show up on the encounter or occurrence page once the upload is finished?
Encounters vs Occurrences/sightings and grouping images together:
It is still very unclear to me what to do when we have a set of pictures, including both individual and group shots, all taken at the same time and place (i.e. that together make up what might be called a single occurrence).
This is significant because the overwhelming majority of our data is grouped this way, and, since zebras are social creatures, group data is something that we’re going to want to include in many instances moving forward.
We were told that if we had multiple individual photos of the same zebra, from the same time and place, that we could put them together on the same line and make them part of the same encounter, and therefore occurence. Similarly, we understand that, if we upload a group picture, it breaks it down into a set of encounters, and then all the encounters detected within that image will automatically be associated to the same sighting or occurrence, and will each individually be assigned all the encounter metadata from that spreadsheet line, as well. The problem, as previously stated, is that our pictures don’t fit neatly into this, and we have many instances of having multiple images, often a combination of different zebras with some repeats, taken as part of the same occurrence. They go on different lines in the spreadsheet and so when uploaded to wildbook will register as a bunch of new and separate occurrences, if any occurence fields are filled out, despite having precisely matching date, time, location and other data. Note that, as per recommendation, we have been uploading our group and individual photos in separate spreadsheets, but we have been using the same spreadsheet template. Additionally, we have decided as a general rule to only have one media asset per line so as to minimize confusion and avoid the possibility of propagating human error into the system(e.g. someone puts two pictures that they think are the same zebra in a line, but it later turns out that they are not). The logic then is that, if two shots of the same, single zebra are in the occurrence, they’ll be matched and labelled as the same individual, even if they get their own encounter pages. I don’t see any problem with this, but if you do, please point it out.
In any case, the bottom line is that, ideally, we’d like to cluster pictures from the same time and place together to (1) better represent our data in the system and (2) so that other researchers can use wildbook’s cool social analysis features.
The only way I see of doing this is by preemptively assigning the images an occurence.occurenceID or encounter.occurenceID (not sure what the difference is between those two). However, I have some reservations about it. Mainly, I don’t know how to check if occurence IDs are unique/already exist, and I am also worried that introducing and enforcing yet another naming convention with multiple people uploading pictures may prove tricky. Is there a way to group pictures together and have the occurenceID be generate automatically? Or is pre-assigning them the best and/or only way to do this? If so, how do we make sure our occurenceIDs are compatible with the system? And do they need to be totally unique, or just unique to the species?
When using occurence fields, do we need to restate all the sighting data on every line adding an encounter to that occurence (e.g. Occurence.individualCount and put 4 in each row)? Or does it work to just leave it blank, entering only the information that applies to that picture and not reentering the metadata that describes the broader group? Which is the better thing to do?
If different information is entered into the same occurence field in different rows corresponding to the same sighting, what will happen? Will one of the entries be overridden?
Are there any super important system limitations I should know about?
Lastly, is there a way to collapse multiple encounters into one sighting, or reassign an encounter to a different sighting once it is already in the system (encounters in this case would presumably either not be part of any sighting or each have their own occurenceID)?
When I upload, some of the Encounter.submitter fields aren’t going through. Not sure what is up with that, but I would like to know, of those fields, which do you think are a good idea to use and which do you think are mostly unimportant? Encounter.submitterID has been going through but we’ve had some issues with fullName/projectName/emailAddress, which I did put in, even though I think they might be a little redundant with submitter ID.
I’m going to answer each question in a different post so I can keep track of what I’m answering:
Bulk import send to identification function and some detection/identification weirdness with Import Task 34264d7f-9058-4321-99d2-1e6a044e39bc:
I have a set of eight pictures of individual zebras (taken on June 11th 2020) that I originally uploaded back before I had administrator permissions to kick off the detection/identification process. The boxes never appeared around the zebras, so later, once I got admin privileges, I deleted the task, uploaded everything again, and set it to go to identification (this is back in December). The process never finished that time either, and none of the zebras got past the “still waiting for detection” label. Meanwhile, Maggie and I have gotten detection to run successfully on other bulk imports. Yesterday, I finally deleted that task, reuploaded, and tried again- except this time only selecting “send to detection” and not “identification”. It worked fine.
It’s possibly that there was just something glitchy with that particular import, but I’m left wondering if there might be an issue with the “send to identification” function. More to the point, I’d like to better understand how sending images directly into the identification process is supposed to work, on both the front and back ends. Once detection is completed, and it runs the matches, are you then able to review the results for each photo before assigning zebras to IDs? Or will it automatically assign them to the match with the highest score? If the program somehow determines that a zebra is an unmatched first encounter, will it generate an automatic alphanumerical ID, and if so, could you change the name after the fact to match an existing naming convention?
You are correct in the assumption that something likely just glitched. Send to Detection sends each image through the detection pipeline; this is what generates annotations (the bounding boxes you see on images). If there are multiple animals in a picture, this is also responsible for creating new encounters for each new animal and makes sure that both encounters have the new metadata. Send to Identification sends the image through the detection pipeline to get annotations and then sends each annotation through the identification pipeline; this generates the proposed matches that you choose from when you select “View Matches”.
At no point does the software ever automatically select a result automatically. This is always a manual process.
Matching with nested location IDs:
I am a little confused about the matching process with zebras sorted into hierarchical locationID categories.
Back in the summer, I remember there being a discussion in which it was recommended that we avoid using tags like Mpala.Central for Encounter.locationID and instead stick to the broader designation Mpala. The reasoning was that Mpala.Central encounters would not be matched against zebras in other Mpala categories and that using a subdivision would constrain the process, when realistically, a zebra could show up again anywhere within the conservancy. I think we were also told or somehow discovered that if a zebra was marked as just Mpala, or if we ran a match against “Mpala” generally, it wouldn’t run against the subcategories and only look at ones with that exact ID, but without further information (Mpala, but not Mpala.North etc), so we have tried to make sure that the pictures we upload have that same location ID.
(this has been mostly with single encounter import and just using the “match results” button, rather than “start another match” and then adding parameters with the checkboxes)
I was wondering if, now, when you run a match against a zebra listed as “Mpala”, if it will still only look at Mpala, or if it will include the zebras that fall into subdivisions of that conservancy, as well. I’d also like to know explicitly whether you can have a zebra labelled as Mpala.Central, and still successfully run the match process against a larger pool.
With bulk import, I’ve noticed that, if you choose to run detection on the pictures in bulk, and then go to match them, you automatically get the dropdown whereby you choose criteria to match against. Why is that? Does it have any implications that I should be aware of? If you check Mpala and all its subcats does the system observe the selection?
Additionally, if you choose to send bulk import images to identification directly, what will happen, in terms of the images they are allowed to match against? Particularly, if there are a mix of location IDs on your spreadsheet, or the location IDs are all within a subcategory of some kind, what will the automatic response of wildbook be, and would it be possible to set it so they are matched against a pool that is above their label in the hierarchy?
By default, matching runs against the current LocationID and everything beneath it. So Mpala matches against Mpala.central, but Mpala.central does not run against Mpala.
At any time, you can manually run a broader match when you select start a new match by adjusting the match criteria:
Expand the LocationID area and click the checkboxes you want to run against.
When doing a bulk upload, you are able to select the match default because it is a subset of data that you are managing manually. Yes, it does respect what categories you select. Yes, you can select one higher than whatever LocationID is assigned to any of the encounters.
What bulk import fields are best for comments?
Frequently our data comes in with little side notes that it would be nice to include. Right now we have Encounter.occurenceRemarks as our column for this in the spreadsheet, but there seem to be a number of different options with a similar function on the wiki- all unconstrained string type fields e.g. Encounter.researcherComments and Occurence.comments. What are the functional distinctions between these, and where do they show up on the encounter or occurrence page once the upload is finished?
You’re using Encounter.occurenceRemarks because, after discussing with Andy this summer, that is what was determined to be most useful and easiest to find. Encounter.researcherComments display on an encounter page under metadata, and can not be edited after being added:
Encounters vs Occurrences/sightings and grouping images together:
It is still very unclear to me what to do when we have a set of pictures, including both individual and group shots, all taken at the same time and place (i.e. that together make up what might be called a single occurrence).
This is significant because the overwhelming majority of our data is grouped this way, and, since zebras are social creatures, group data is something that we’re going to want to include in many instances moving forward.
We were told that if we had multiple individual photos of the same zebra, from the same time and place, that we could put them together on the same line and make them part of the same encounter, and therefore occurence. Similarly, we understand that, if we upload a group picture, it breaks it down into a set of encounters, and then all the encounters detected within that image will automatically be associated to the same sighting or occurrence, and will each individually be assigned all the encounter metadata from that spreadsheet line, as well. The problem, as previously stated, is that our pictures don’t fit neatly into this, and we have many instances of having multiple images, often a combination of different zebras with some repeats, taken as part of the same occurrence. They go on different lines in the spreadsheet and so when uploaded to wildbook will register as a bunch of new and separate occurrences, if any occurence fields are filled out, despite having precisely matching date, time, location and other data. Note that, as per recommendation, we have been uploading our group and individual photos in separate spreadsheets, but we have been using the same spreadsheet template. Additionally, we have decided as a general rule to only have one media asset per line so as to minimize confusion and avoid the possibility of propagating human error into the system(e.g. someone puts two pictures that they think are the same zebra in a line, but it later turns out that they are not). The logic then is that, if two shots of the same, single zebra are in the occurrence, they’ll be matched and labelled as the same individual, even if they get their own encounter pages. I don’t see any problem with this, but if you do, please point it out.
In any case, the bottom line is that, ideally, we’d like to cluster pictures from the same time and place together to (1) better represent our data in the system and (2) so that other researchers can use wildbook’s cool social analysis features.
The only way I see of doing this is by preemptively assigning the images an occurence.occurenceID or encounter.occurenceID (not sure what the difference is between those two). However, I have some reservations about it. Mainly, I don’t know how to check if occurence IDs are unique/already exist, and I am also worried that introducing and enforcing yet another naming convention with multiple people uploading pictures may prove tricky. Is there a way to group pictures together and have the occurenceID be generate automatically? Or is pre-assigning them the best and/or only way to do this? If so, how do we make sure our occurenceIDs are compatible with the system? And do they need to be totally unique, or just unique to the species?
When using occurence fields, do we need to restate all the sighting data on every line adding an encounter to that occurence (e.g. Occurence.individualCount and put 4 in each row)? Or does it work to just leave it blank, entering only the information that applies to that picture and not reentering the metadata that describes the broader group? Which is the better thing to do?
If different information is entered into the same occurence field in different rows corresponding to the same sighting, what will happen? Will one of the entries be overridden?
Are there any super important system limitations I should know about?
Lastly, is there a way to collapse multiple encounters into one sighting, or reassign an encounter to a different sighting once it is already in the system (encounters in this case would presumably either not be part of any sighting or each have their own occurenceID)?
I think the core questions here are
what is the difference between occurrence.occurrenceID and encounter.occurrenceID?
Functionally, there isn’t one. We recommend using Encounter.occurrenceID. See https://docs.wildme.org/docs/researchers/bulk_import
does Wildbook have a way to automatically generate Occurrence IDs?
Yes this happens every time you submit an encounter. If you submit a photo that gets broken into multiple encounters, they all get assigned the same occurrenceID. If you submit multiple photographs on the same line, they all get the same occurrenceID.
Can an automatically generated ID follow a specific format?
No. It is a randomly generated unique ID. If you need it to follow a format, you need to enter that format manually.
How do we make sure formatted IDs are compatible with the system? Restricted to latin alphanumeric characters (a-z, A-Z, 0-9), - and _ This information can be found in the documentation.
Do occurrenceIDs need to be unique to the system or to the species?
To the system. There are cases where a sighting can include multiple species, and the system reflects that.
When using occurence fields, do we need to restate all the sighting data on every line adding an encounter to that occurence (e.g. Occurence.individualCount and put 4 in each row)? Or does it work to just leave it blank, entering only the information that applies to that picture and not reentering the metadata that describes the broader group?
We recommend repeating the occurrence fields. This prevents any issues that can be caused with multi-threading.
If different information is entered into the same occurence field in different rows corresponding to the same sighting, what will happen? Will one of the entries be overridden?
Only one set of information is maintained at the occurrence level.
Lastly, is there a way to collapse multiple encounters into one sighting, or reassign an encounter to a different sighting once it is already in the system (encounters in this case would presumably either not be part of any sighting or each have their own occurenceID)?
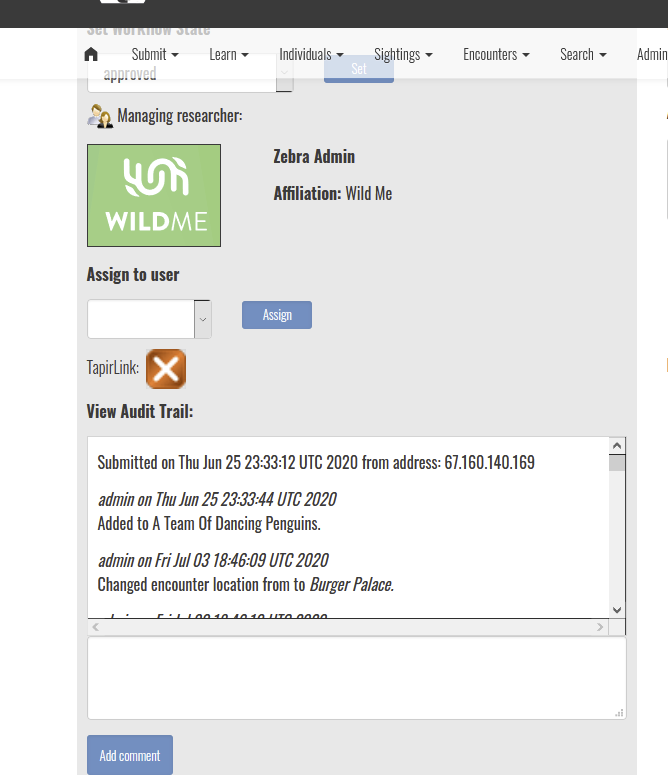
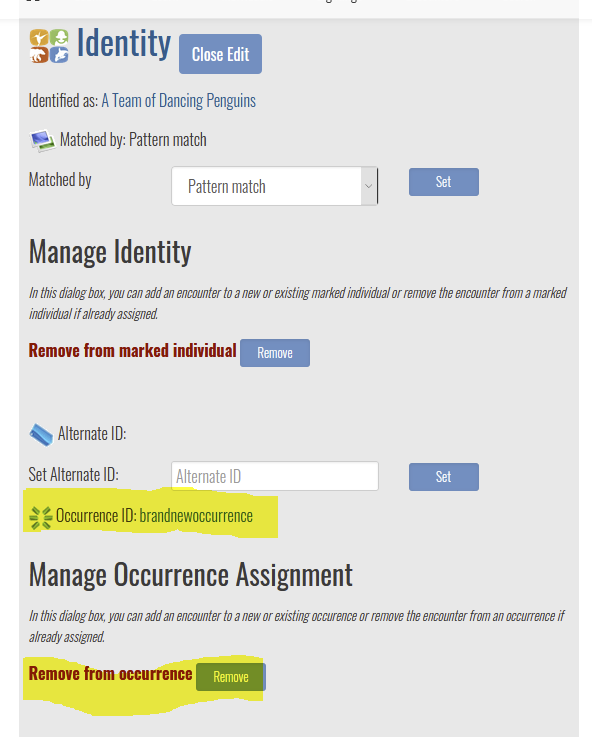
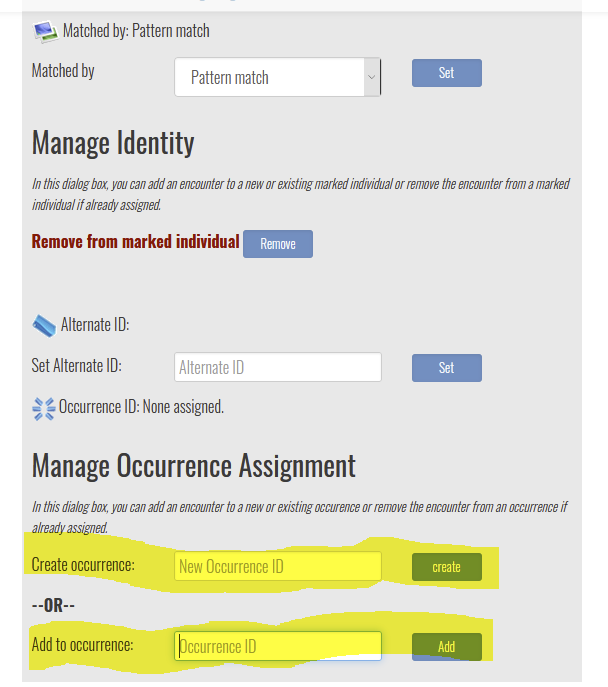
I do not understand what you mean by “collapse multiple encounters into one sighting”. A sighting is made of multiple encounters. If you want to reassign an encounter to a different sighting, go to the encounter page, and click the Identity Edit button.
Either provide a new ID using the “Create” option or enter the name of an occurrence in the system with the “Add” option. This field has type-ahead capability, so you can type part of the name you are looking for and select from the list.
These fields are not redundant and actually serve different purposes. Encounter.SubmitterID is used to associate and encounter with the account that will own the data.
The Encounter.submitterX fields are used to provide updates to additional users who are associated with the data. Here is the information available in the documentation about these fields:
Name
Type
Example Value
Description
Encounter.submitterX.affiliation
String
Joe’s Safaris
Unconstrained string to indicate an organization the encounter submitter is associated with. Values of “X” from 0 to infinity are iterated until a sequence value is not found. Does not save unless submitterX.emailAddress is also reported.
Indicate the email of the encounter submitter. Values of “X” from 0 to infinity are iterated until a sequence value is not found.
Encounter.submitterX.fullName
String
Joe Smith
Provide the full name of the encounter submitter. Values of “X” from 0 to infinity are iterated until a sequence value is not found. Does not save unless submitterX.emailAddress is also reported.
Without seeing your data, I cannot diagnose what is going wrong, but here are some common troubleshooting steps:
You are not updating X in the column header to be a number.
You are not including the emailAddress, which is necessary for all fields to be reported.
@fiona_logansankey@maggieliebich I dug into this and answered everything that I could think to address. If you need additional clarification, I’m leaving this thread open for a week, so feel free to post here in response. In the future, you can request a call to work through something where you have this many open questions.
Hi Tanya,
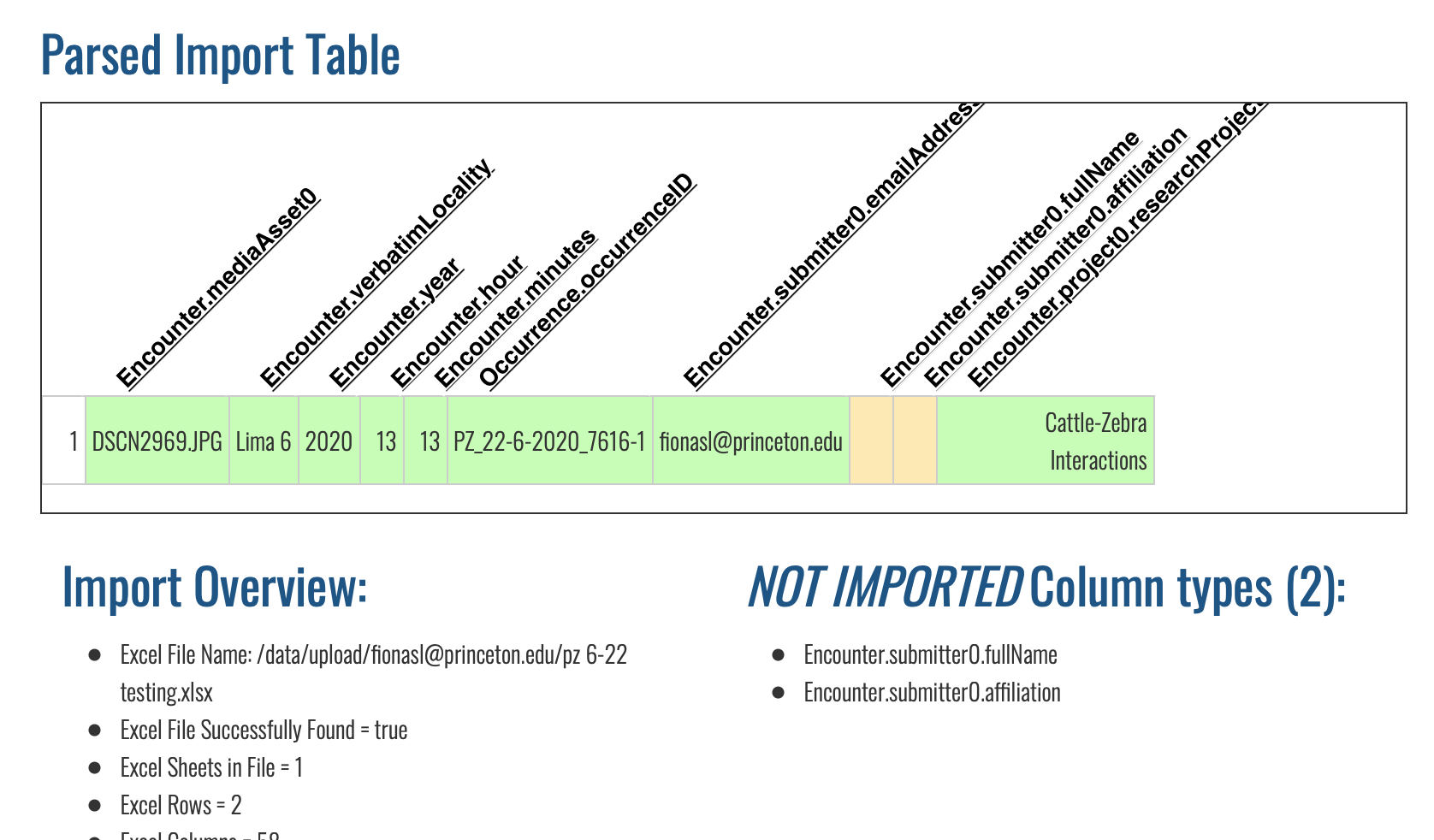
I have been including an email address and using ‘0’ where the X appears in the column header documentation. Despite these efforts, the information for submitter0.fullName and submitter0.affiliation never go through. See screenshot below from a recent test import. This has been true of all our bulk imports so far.
Additionally, where does Occurrence.groupComposition propagate to? I recently tried using it, and although the column made it through the import, I could not find the information I had inputted anywhere on either the sighting or encounter pages.
Occurrence.groupComposition does not display in the UI on the zebra wildbook. I’m not sure it does on any Wildbook.
As for the submitter fullName and affiliation: these are tied to the account associated with the email. If you are linking to an account that already exists, such as the one in your screenshot, it will take the information that is associated with your account, not what it is in the spreadsheet. You can change this information under Administer > My Account.
Hey Tanya!
Thanks so much for the clarification! It helps a lot. In that case I think I will just not use Occurrence.groupComposition and stick with putting that kind of info in as Encounter.occurrenceRemarks.
Just so you know, Maggie recently made another post on community about some issues we’ve been having. It got put in as uncategorized though so I’m worried you may not have seen it. We are having some serious issues with detection and matching (read: they are not working) and since you are most familiar with our situation it would be great if you could take a look at it. I think we may have overloaded the server or something - not really sure.
It also has a repeat of my follow up questions from a week ago tacked on, so feel free to disregard that chunk.
Best,
Fiona