What is the entire URL out of the browser, exactly where the error occurred?
_Flukebook | Login
Can you describe what the issue is you’re experiencing?
After importing dataset (Cetamada’s dataset) containing only fluke MediaAssets, it seems that multifeature detection was applied automatically. Indeed, there is a double annotation for almost all Fluke images : one “Fluke” annotation (for which the annotation box is usually very large) and one “dorsal fin" annotation at the tip of the Fluke (so an erroneous annotation). Furthermore, Flukebook seems to create a new encounter for the “dorsal fin” annotation, probably because it considers it as a different individual (c.f.https://docs.wildme.org/docs/researchers/overview#wildbook-terminology).
Redrawing the Fluke annotation and removing the dorsal fin annotation could be carried out manually, but it would be a long process. In fact, Cetamada’s dataset contains more than 1500 encounters. So we were wondering the following:
Do we have to redraw every Fluke annotations or does the identification process work with a large annotation box around the Fluke ? Will it have an impact on the efficiency of the matching algorithm if we leave the large box ?
From the back office, would you be able to remove all dorsal fin annotations from Cetamada’s data ?
Would you be able to re-run the automatic Fluke annotation on Cetamada’s data, to get a smaller annotation box?
Further, we are trying to figure out why the “number of candidates” on the matching result page varies between matchs within a project. Does the annotation “viewpoint” have an impact on the number of images an encounter is matched against? If it is the case, is there a way to check the “viewpoint” of the annotations, and change it if needed ? For humpback whale flukes, viewpoint is expected to be from the “back” for all annotations so the number of candidate images should not change. We would like to make sure that within our project, which only include Fluke encounters, images are matched against all other images from that project.
I re-ran the detector on your flukes using a different ML model, and I am seeing improved bounding boxes. The previous annotations were created by an early detector that has since been replaced.
Can you please confirm?
Does the annotation “viewpoint” have an impact on the number of images an encounter is matched against?
Yes, as does location (e.g., “Saint Marie”) and feature type (e.g., dorsal versus fluke).
Thank you for your answers and for having re-ran the detector on our fluke images.
After checking approximately 16% of the Cetamada’s encounters (i.e. 314 encounters out of 1975), we also note an improvement of the bounding boxes. In fact, the majority (99%) of the images are well annotated and all of them have a whale_fluke IA Class.
However, other issues occurred. We found out that almost all images have been duplicated in two separate encounters (each encounter having a specific number) although only the initial image (i.e. image from the initial encounter) have been annotated. This duplication may have an influence on the total number of encounters. Moreover, images are sometimes duplicated in the same encounter but, here again, only the initial image is annotated. Could you remove the duplicates ?
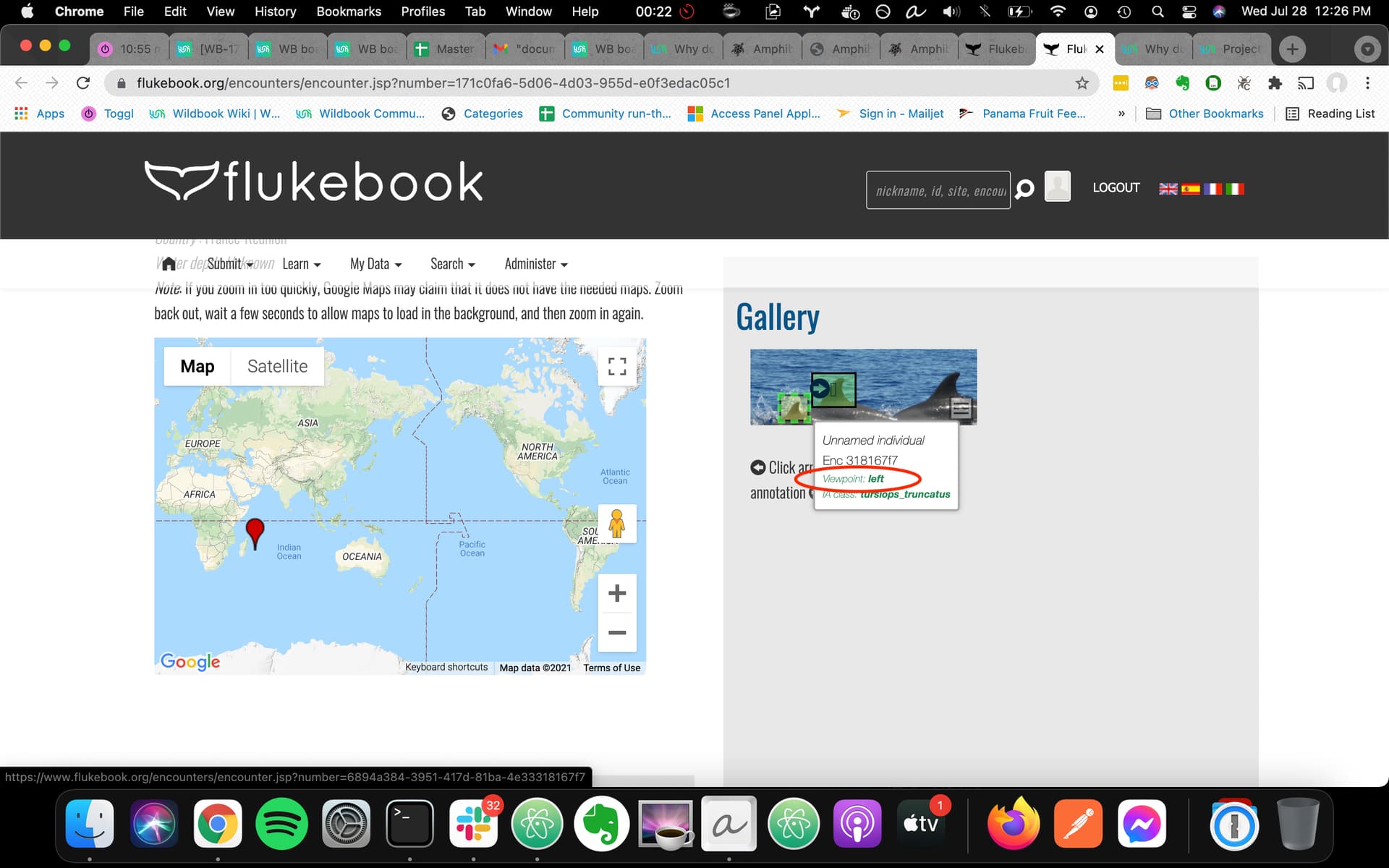
Concerning the influence of the “viewpoint” on the number of candidates considered by the matching process, we would like to check what viewpoint has been given to each annotation. It seems that it should be displayed with the annotation, together with the IA class (as someone mentionned previously ong the blog https://community.wildme.org/uploads/default/original/1X/54bb904003a9b04d89314f4f997751cec21bebc4.jpeg ). But in our case, it doesn’t show up for Fluke annotations. Is that a bug that could be fixed ?
Also, if the “Location ID” have an influence on the number of candidates, how can we make sure that encounters are systematically match against all encounters within a project, irrespective of their location ID? Could you please explain precisely how the matching process workswithin a project framework ? We need to understand the process to reduce bias in our studies.
At last, when running the matching, system is stopping after having run 2 matchs. The“match result” page is frozen for tens of minutes and the message “attempted to match” is displayed, no longer allowing matchs to be made.
Thanks for advance for your answers which will clarify many of our questions.
{kind=link}