Jason,
Thank you for your response.
Following these explanations, we re-run the matching process on several encounters on 2021-09-06 and within the same projet (c.f. Indocet’s Mn project at this URL : Flukebook | Login). Here is how we proceeded (as indicated in WildMe Docs) : after clicking on “Start match” (the button turned red), we clicked on “Match results”.
Following these steps, when clicking on “view” latest results, the match results were not updated and the old timestamp was still being displayed. Also, the identification status (initially “pending”) has not been updated (c.f. screen shot below).
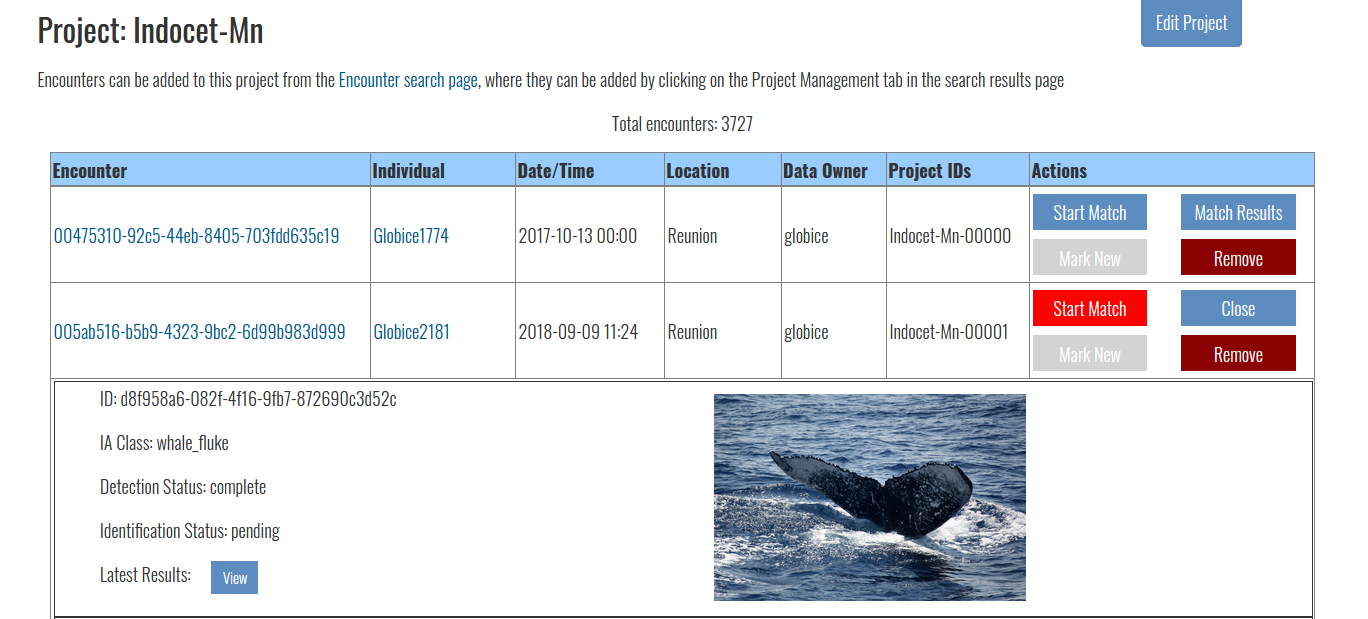
Is the identification status supposed to change to “complete” on this page when the matching process is done ? Do you know why the matching process gets stuck at this stage ? We also tried with a VPN, but it didn’t work any better. Further, could you please explain what are the different “identification status” (some encounters have been matched and have a project ID, but still have an “undefined” identification status) ?
In addition, as mentioned in a previous post (c.f. Automatic detection error - #3 by paul_lallement), the matching time increases considerably after 2 matches and the message “attempted to match” is displayed either for some algorithm results or for all of them (c.f. https://www.flukebook.org/iaResults.jsp?taskId=d30ec6a7-4184-4fb1-af73-34914a3a398f&projectIdPrefix=Indocet-Mn-#####). Any idea of where it might come from?
Thank you in advance for your precious answers.
Best regards,
Paul and Violaine