Hi Jason,
Thank you for your answers and for having re-ran the detector on our fluke images.
After checking approximately 16% of the Cetamada’s encounters (i.e. 314 encounters out of 1975), we also note an improvement of the bounding boxes. In fact, the majority (99%) of the images are well annotated and all of them have a whale_fluke IA Class.
However, other issues occurred. We found out that almost all images have been duplicated in two separate encounters (each encounter having a specific number) although only the initial image (i.e. image from the initial encounter) have been annotated. This duplication may have an influence on the total number of encounters. Moreover, images are sometimes duplicated in the same encounter but, here again, only the initial image is annotated. Could you remove the duplicates ?
Concerning the influence of the “viewpoint” on the number of candidates considered by the matching process, we would like to check what viewpoint has been given to each annotation. It seems that it should be displayed with the annotation, together with the IA class (as someone mentionned previously ong the blog https://community.wildme.org/uploads/default/original/1X/54bb904003a9b04d89314f4f997751cec21bebc4.jpeg ). But in our case, it doesn’t show up for Fluke annotations. Is that a bug that could be fixed ?
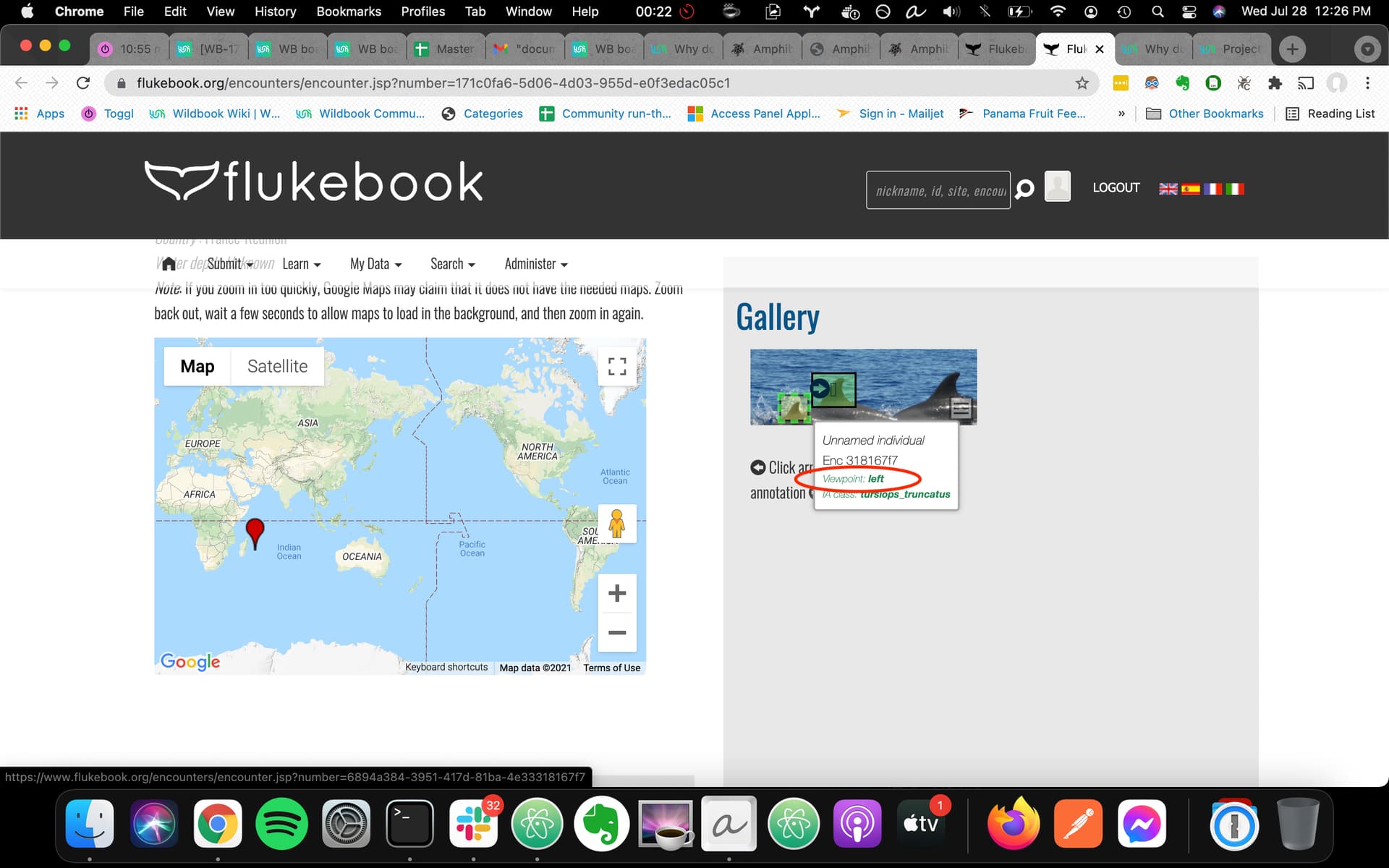{kind=link}
Also, if the “Location ID” have an influence on the number of candidates, how can we make sure that encounters are systematically match against all encounters within a project, irrespective of their location ID? Could you please explain precisely how the matching process works within a project framework ? We need to understand the process to reduce bias in our studies.
At last, when running the matching, system is stopping after having run 2 matchs. The “match result” page is frozen for tens of minutes and the message “attempted to match” is displayed, no longer allowing matchs to be made.
Thanks for advance for your answers which will clarify many of our questions.
Best regards,
Paul and Violaine