Flukebook / Mac Os High Sierra 10.13.6 / Firefox, Chrome and Opera / Admin
We have some questions about how the matching process works within a project.
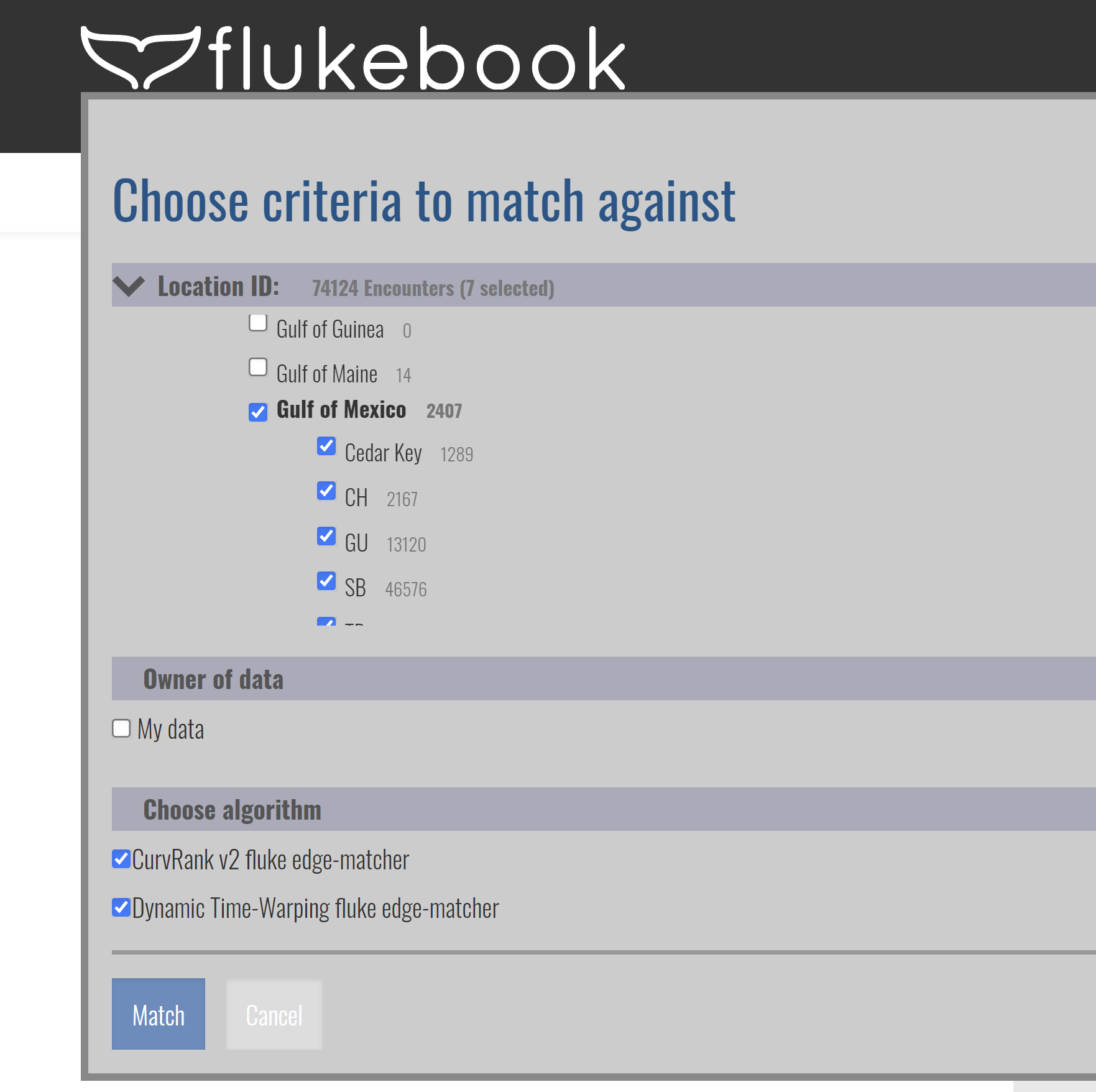
Indeed, the “Location ID” affects the number of candidates considered by the matching process. This is quite confusing as within a project we would expect that matching is done irrespective of the location ID. How can we make sure that encounters are systematically match against all encounters within a project (even if they have different location ID)? Could you please explain precisely how the matching process works within a project framework ?
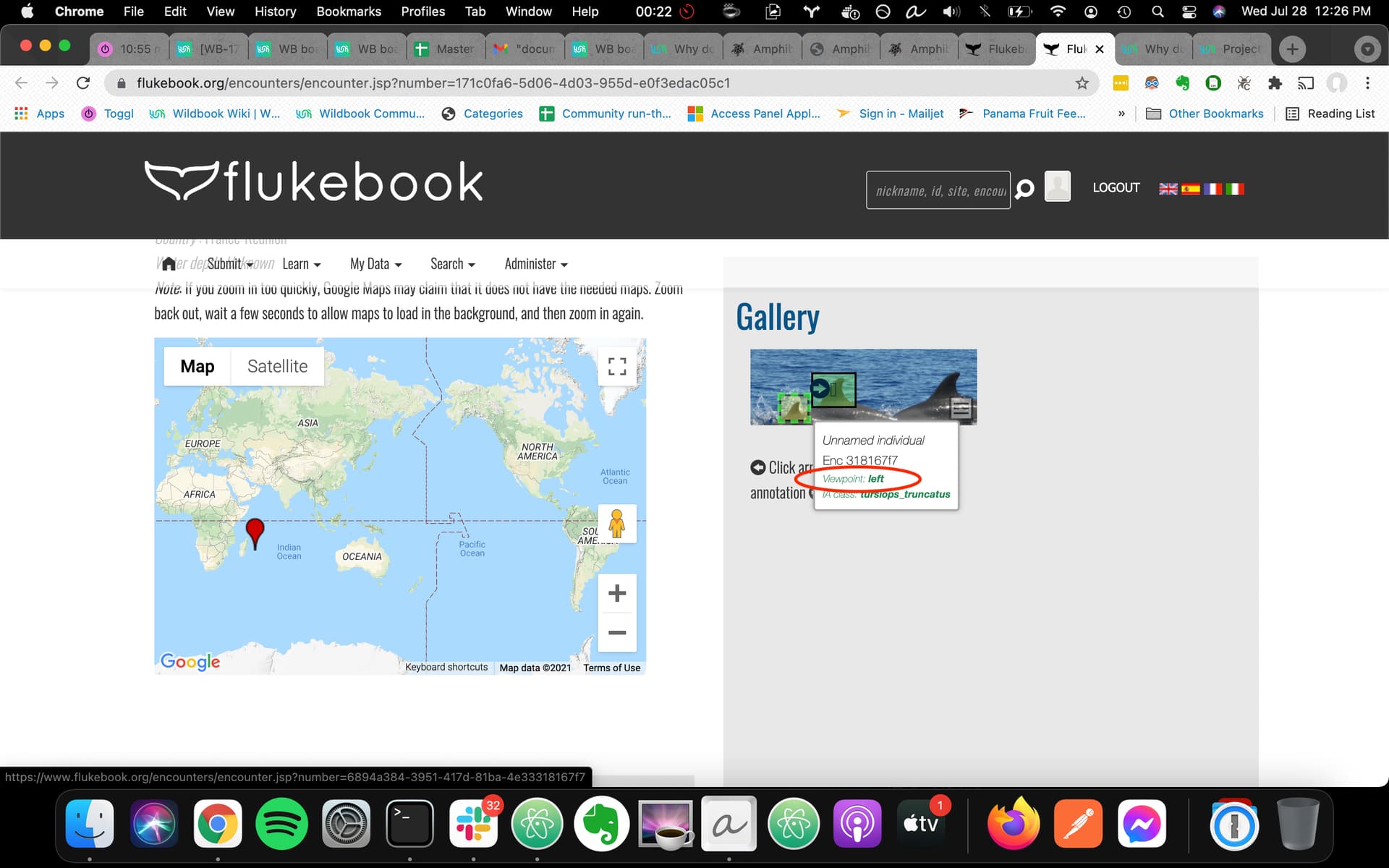
Since the “viewpoint” have also an influence on the number of candidates, we would like to check what viewpoint has been given to each annotation. In our case, it doesn’t show up for Fluke annotations although it is displayed for dorsal fins (https://community.wildme.org/uploads/default/original/1X/54bb904003a9b04d89314f4f997751cec21bebc4.jpeg ). Could that be fixed ? Or does it means that Fluke don’t have a viewpoint?
Thank you in advance for your answers, that will help clarifying the process, as we want to make sure there is no bias when conducting matching within the Indocet project.
If you kick off a match for an Encounter from the Project page, matching will occur within the project but locationID will NOT be considered. I verified this by looking at the query itself in the database.
In all cases, filtering occurs by species and iaClass (the type of annotation, so that we don’t compare fins to flukes), such as “whale_fluke”. While you can set a viewpoint for a fluke, it is explicitly left out for humpbacks.
I would like to thank you for your time in responding and for checking the code. Our understanding of how the matching process works within a project in now enhanced.
Candidates are the number of annotations (literally the green bounding boxes in the Encounter images) that we tried to match against. These are filtered - as previously discussed - by species, location ID, feature type (e.g., whale_fluke), and even project depending on user selection.
If I’m given two random match results that have significantly different candidate numbers, as you included, it is safe to assume they asked different questions, such as one filtering by project and the other not.
If I ask the same question of two different flukes from Reunion from these Encounters:
One has 3878 candidates and the other has 3879, showing good consistency in what we tried to match against. However, they are off by 1. Why? Because one of the Encounters has two annotations, and we don’t try to match against the same Encounter (therefore there were only 3878 whale_fluke candidates to try to match against in Reunion). So asking the same question can lead to slightly different numbers.
Thank you for your reactivity and for your precious answers.
Although the number of candidates is the same when encounters are filtered by Location ID, as shown in your example with La Réunion, it seems that it doesn’t work when matching is conducted within a project (rather than matching random individuals from the encounter page).
Indeed, when matching encounters (for ex: 1st and 2nd links below) within the same project (Indocet-Mn project, c.f. 3rd link below), the number of candidates is respectively 3425 and 4450, while they should be matched against the same number of candidates. Do you have any idea of why the number of candidates differs in this specific case (i.e. within a project framework)?
…almost one year apart from the second link (2021-07-15). Match results are snapshots of what matched at the time. Re-running that fluke yesterday produced yet a different result:
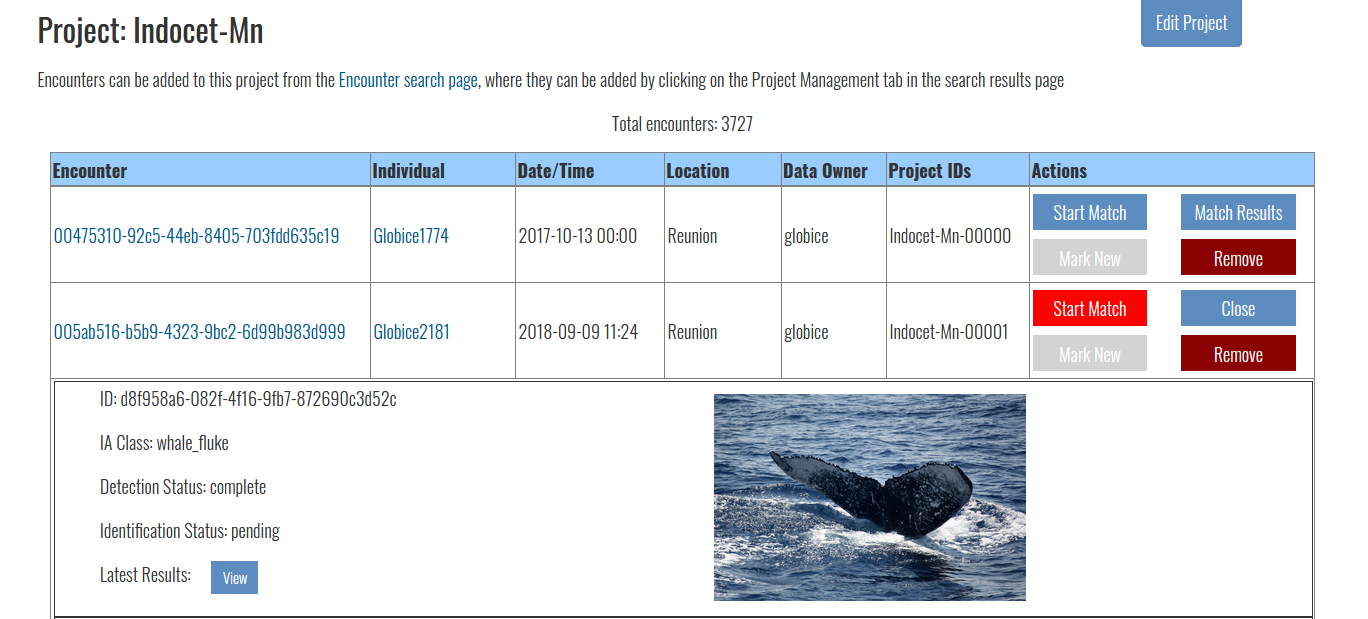
Following these explanations, we re-run the matching process on several encounters on 2021-09-06 and within the same projet (c.f. Indocet’s Mn project at this URL : Flukebook | Login). Here is how we proceeded (as indicated in WildMe Docs) : after clicking on “Start match” (the button turned red), we clicked on “Match results”.
Following these steps, when clicking on “view” latest results, the match results were not updated and the old timestamp was still being displayed. Also, the identification status (initially “pending”) has not been updated (c.f. screen shot below).
Is the identification status supposed to change to “complete” on this page when the matching process is done ? Do you know why the matching process gets stuck at this stage ? We also tried with a VPN, but it didn’t work any better. Further, could you please explain what are the different “identification status” (some encounters have been matched and have a project ID, but still have an “undefined” identification status) ?
Every time you try to match a fluke, you can choose multiple algorithms, so for a single match with four algorithms selected, the system will need to get through four in a row before going on to the next Encounter and its matching. You can speed up matching by selecting fewer algorithms per Encounter. Otherwise, you will notice a slow down in successive Encounters as the system processes multiple algorithms for each Encounter. Other users may also be requesting matching jobs, and this may impact your response time.
When watching a match results page, it will attempt to periodically refresh to see if matching results are done. After multiple attempts, it will time out. You can always refresh the page to restart the checking. If you have kicked off multiple Encounter matching jobs, it may take awhile before match results appear.
I have filed ticket WB-1785 to make some improvements here. Two things that would help.
A status button letting you know the “Start Match” button kicked off the new matching job. I confirmed it is working, but it is not providing any feedback, which it should.
Connecting the new “Start Match” matching process to the “Match Results” button. I confirmed that “Start Match” is working, but because it is an asynchronous process, the “Match Results” button takes some time to get linked to the new set of match results. I’ll see if this can be linked better. Until then, refreshing the page will eventually show the new task matched to the “Match Results” button. Alternatively, kicking off the match from the Encounter page itself may provide better feedback.


{kind=link}