I hope you are well. We are currently working through uploading a lot of images to Wildbook via Bulk Import. The upload and detection were working really well for the first couple Bulk Imports, but there seems to be a glitch or we have started doing something wrong because now detection isn’t working on any of our bulk imports. Is this just a result of a large number of uploads, or are we doing something wrong? For some of the imports detection has occurred but the matching isn’t working and it just says “attempting to fetch results” or “still waiting for detection” even though the zebra is boxed, and for some detection still hasn’t happened.
Imports without detection: 07ae2658, 09b4d263, dc5ebe99, b593804e, a92166d1, 5e09412f, ffb13660, eac66184, 3a148474
Imports with detection but matching isn’t working: c0c9a9fd, e4645740, 6d4eb036, 28194bdd, 62b3bb0a, 7720f997
I also uploaded an import of 28 photos on 2/08 and I sent the import to identification instead of detection. Wildbook says that it is still running IA on the import. I am unable to delete the import on my end and I was wondering if you could delete it for me? The import ID is 4f86400c.
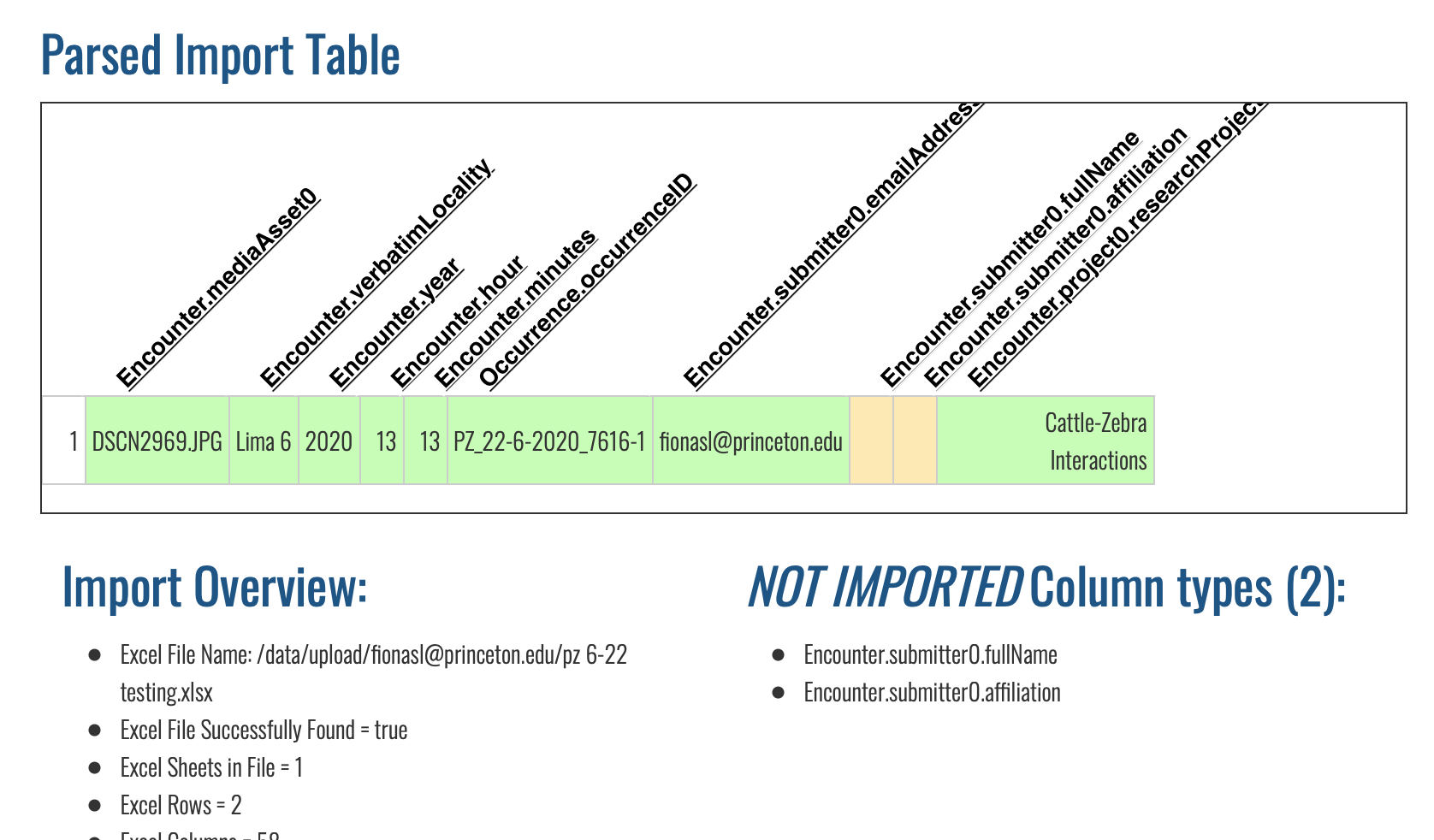
Also, we are having some issues with the submitter0.fullName and submitter0.affiliation. We have been including an email address and using ‘0’ where the X appears in the column header documentation. Despite these efforts, the information for submitter0.fullName and submitter0.affiliation never go through. See screenshot below from a recent test import. This has been true of all our bulk imports so far.
Additionally, where does Occurrence.groupComposition propagate to? I recently tried using it, and although the column made it through the import, I could not find the information I had inputted anywhere on either the sighting or encounter pages.
Hi @tanyastere
We’ve also noticed that as a rule, the parsed import table seems to only display a small-ish subset of our spreadsheet columns, as you can see above. The other data still makes it through, so this isn’t a high priority item. That being said, it would be nice to be able to actually review the full spreadsheet in the preview.
The fact that detection/zebra identification and matching doesn’t appear to be working, however, is a serious problem. My guess is that this all has to do, at least partially, with processing power. We’re planning to put quite a lot of data into the system over the next few months, so we probably going to need a bit more oomph.
Thanks so much for your time and continuing to put up with us.
Best,
Fiona
Hey yall,
This is actively being looked at but I don’t have an answer for you yet. @MarkF has been digging into it and will report back as he is able to figure things out or has questions.
Hi, Fiona and Maggie!
Coincidentally, I’ve noticed the exact same thing in the zebra Wildbook. Still getting to the bottom of this. It’s my highest-priority item for the end of this week!
I strongly suspect that it has nothing to do with processing power, as I am able to see from my end that jobs are not even entering the detection queue.
Will report back as I learn more. The issue is being tracked internally under ticket WB-1497.
Thanks,
Mark
I’m having some trouble even getting detection to work on zebra using the single-file upload currently, much less the bulk import, and I would assume that you would experience similar.
We had an IA server outage earlier today/yesterday that affected zebra, and I’m trying to see whether that has added a new, temporary layer of complexity to this puzzle.
I have some questions out to other members of the staff and am hopeful that there will be some more support for the questions soon.
In the meantime, I would to encourage you to pause your bulk imports if you can.
Thanks,
Mark
Hi again, Maggie!
This is just here to reassure you that we haven’t forgotten about you. This ticket actually helped us uncover a Wildook-wide bug, and the ticket has been updated to reflect that. We’re (still) on it!
-Mark
Hi, Maggie!
I’m glad to hear. WB-1497 was a tricky one (it was failing only under certain circumstances), so I’m not surprised that it was working normally most of the time anyway!
It passed code review and is on its way to QA, so hopefully it will be a standard fix soon! And it’s actually already up on the zebra Wildbook anyway I believe.