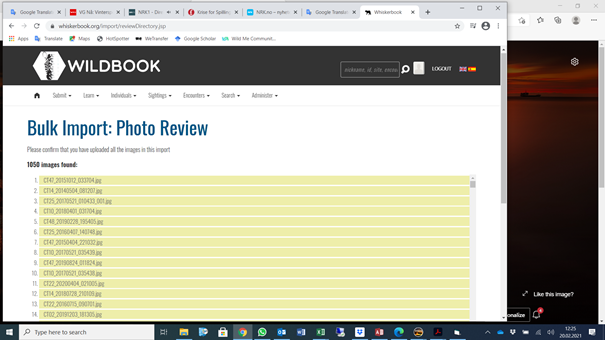
Hi again,
I still have problems with understanding where I can see and control/accept the results after the processing. I suppose I must look at Match Results at the page below:
When I do that I get the pages as shown below. I still cannot see the actual results. I wonder if my database is too large for the system, or I am too far away, or is it something else I do wrong. Is the process described anywhere step by step so that I can learn and understand it better?
Hey there,
Your images came through fine. I’m getting some inconsistent behavior looking at your different encounters. Some are working just fine, but the one for Pa-0011 is concerning. I’m going to move this to a separate thread for us to track because you may have found a bug, but I need to confirm with the technical members of the team.
Hey there!
Some news. The short of it is:
We figured out the issue, and we’re in the middle of fixing it.
The long of it is:
If you send a bulk import task to identification, it runs all of the match jobs as a single job. If you do a smallish import, this is something that can go unnoticed, but if you do an import of more than 100, it makes the page slow and hard to load.
We are fixing this by making bulk import ID jobs run as individual jobs.
What you can do as we work on this fix: manually run ID jobs.
Go to the encounter, go to the gallery, click the hamburger menu, and click “start new match”. This will create a single match job that will not crash the page.
Thank you for the information! I am sorry I made all this trouble! I actually tried to delete the whole import but was not allowed. It is ok for me if you delete it and then I can start with a smaller import of about 100 pictures. Please advice!
Hey @oystein.wiig,
You didn’t cause anything! You helped us identify an issue we need to address, so really we should be saying thank you!
I went ahead and deleted the import for you, so you can start smaller imports as a workaround for now. Thank you for your understanding and willingness to work with us.
Thank you for the information. I just tried to upload a new set of 70 pictures. Apparently the old upload was still there so the 70 new were just added to the all the old ones that I thought were removed by you. So I stopped the new upload. Please advice again!
Cheers
Øystein
Hi Tanya,
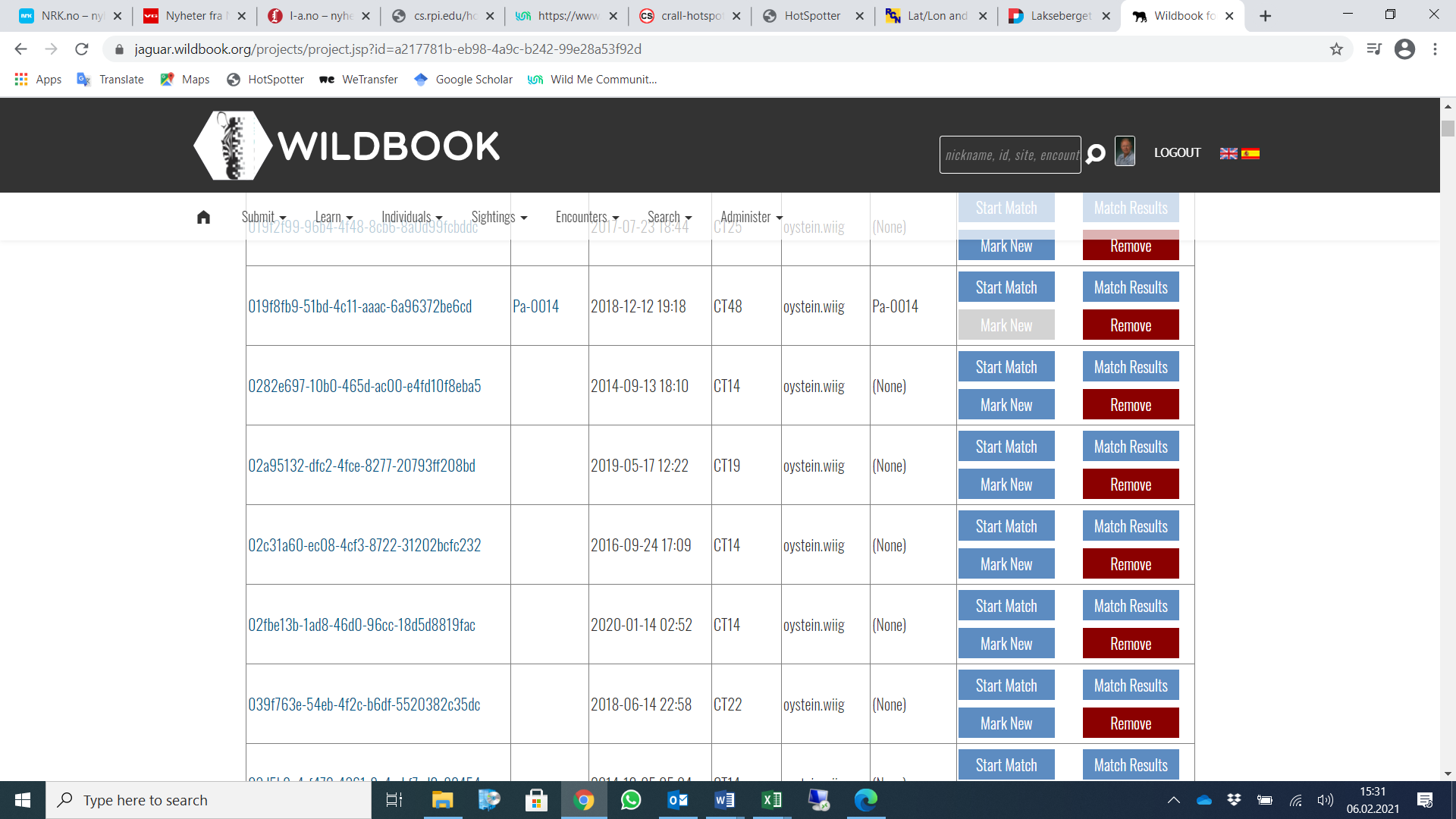
The screenshots below indicate for me that the 980 pictures I uploaded the first time is still in the system. My understanding was that you had removed them all. I have uploaded 70 new pictures that needs to be processed. The new pictures are among the 980 old ones but with a slightly different file-name. Would it be an idea to make another project of those?
Cheers
Øystein
Hi Tanya, I just wonder what is the status of the issues I took up with you. I bulk imported 70 photos five days ago. Will you send them through the IA process?
Thank you for your help!
Cheers
Øystein
Hey there,
The bulk import has been run, and I’m seeing annotations on the images. Let me know if there’s other ones you upload that you need run. I am presently working to get some upgrades in that will let you run them yourself so you don’t have the delay of waiting on us.
Hi, Øystein!
We are still working on this.
In case it’s pertinent information, you should know that when you delete a bulk import, it removes records from the database but does not remove the images from the server. I don’t think that any action is needed on this front, but perhaps it satisfies your curiosity about why you were still seeing the image files.
There is a fix that has now been deployed for the issue. We were tracking it under WB-1440, and had seen on multiple platforms identification results for the entire upload grouped around each encounter it contained. Please let us know if you try an import again and the issue is resolved for you.
Hi Collin, thank you for the information on the fix! Unfortunately I do not quite understand what is going on with my data handling and hope for some clarifications! I have bulk imported pictures at two occasions. February 1 2021 I imported about 970 pictures (Import ID 00513210) and February 19 I imported 70 pictures (Import ID 47f8c335). The first import did not run through the pipeline because it was too big and Tany said she should remove the whole import of 970 pictures. At the same time I imported the second batch (70 pictures) containing some of the same pictures as in the first batch. All these pictures from both imports are now included in my project Paragominas, which contains 1047 encounters. As pointed out earlier I still do not understand that the first 970 pictures were removed, since they are all there under Bulk Import and in project Paragominas. As suggested by Tanya I started to manually add annotations and identifications of all these 970 pictures. It takes me about 10-15 minutes to run each picture and to run about 1000 will take a lot of time!! I thought/hoped that when you had fixed the bulk import bug, you would be able to run all my pictures in project Paragominas through the automatic pipeline, alternatively keeping those I have done manually out of the process. Have I misunderstood this? Should I alternatively remove my project Paragominas with all the pictures from Whiskerbook and then start from scratch with a new bulk import of 970 pictures so that the fix you now have made allow all my pictures to run through the automatic detection pipeline? I am very impressed by your automatic identification system and should like to apply it for my jaguar data as well as for other species I have in my files. Right now I have gone back to run HotSpotter on my computer to identify my jaguars because that is much more time efficient for me in relation to the manual identification process I have done in Whiskerbook so far. May be it could be possible to have a direct call about the issue in the near future to better clarify my obvious misunderstanding! J
Thank you again for your support!
Cheers
Øystein
My apologies for being unclear. The issue we have fixed is where you made a bulk upload, it processed but the identification results could not load or were slow to load on each individual encounter. This was due to the software struggling to display results for all images in a larger upload.
We have divided this into smaller tasks and the identification results should be easily accessible for each encounter you submit in the bulk upload where an animal was found.
This will not affect images where an animal was not found by the detection process, and therefore not sent to identification at all. Images like this will still need manual annotation or a retraining process for the detection model.
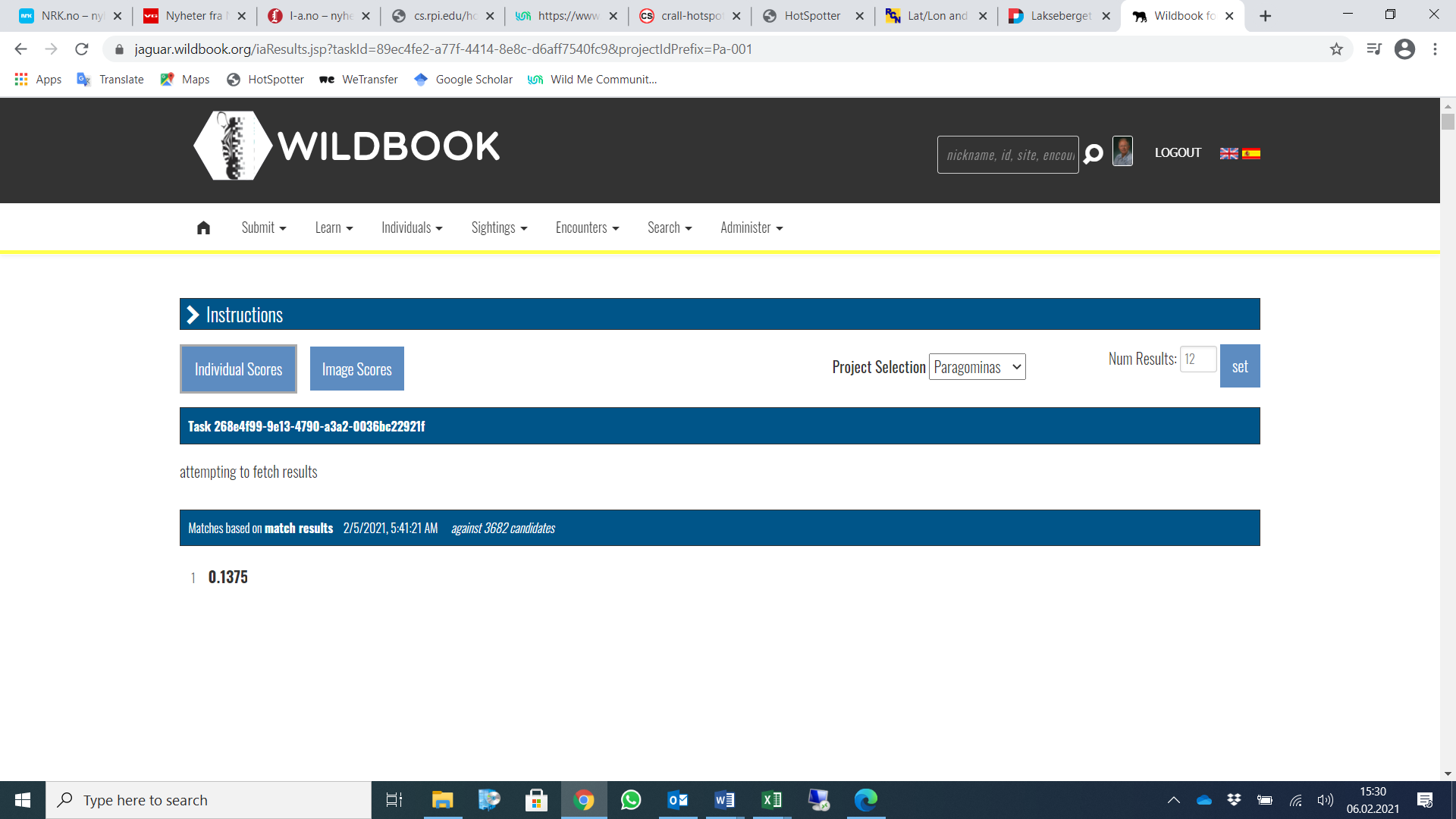
 Cheers
Cheers