Hi!
I’m Louise and I’m working on sperm whales with Flukebook. It’s been three times that I’ve tried to send my bulk import to identification but it doesn’t work.
The first time that happened I deleted the bulk import and resubmitted. I first thought it was because, for each encounter, I had GPS coordinates but no location ID so when I would send to identification, it would run in the all world instead of just the Caribbean Sea. I fixed this by adding the new column “Encounter.locationID”.
Then, I tried again and this time, there was an issue with the “send to detection” function which was indicating 0/222 all day. I deleted the bulk import and reloading the spreadsheet. Then, I tried to send to detection at home during the evening, assuming that there would be less persons trying to match things at this time, and the “send to detection” button worked properly. So here I am, trying to send to identification and letting my computer run all night, to find “gave up trying to match” message in the morning and later on, the “attempting to fetch results” message.
I really don’t know what to try next so I’m contacting you for help
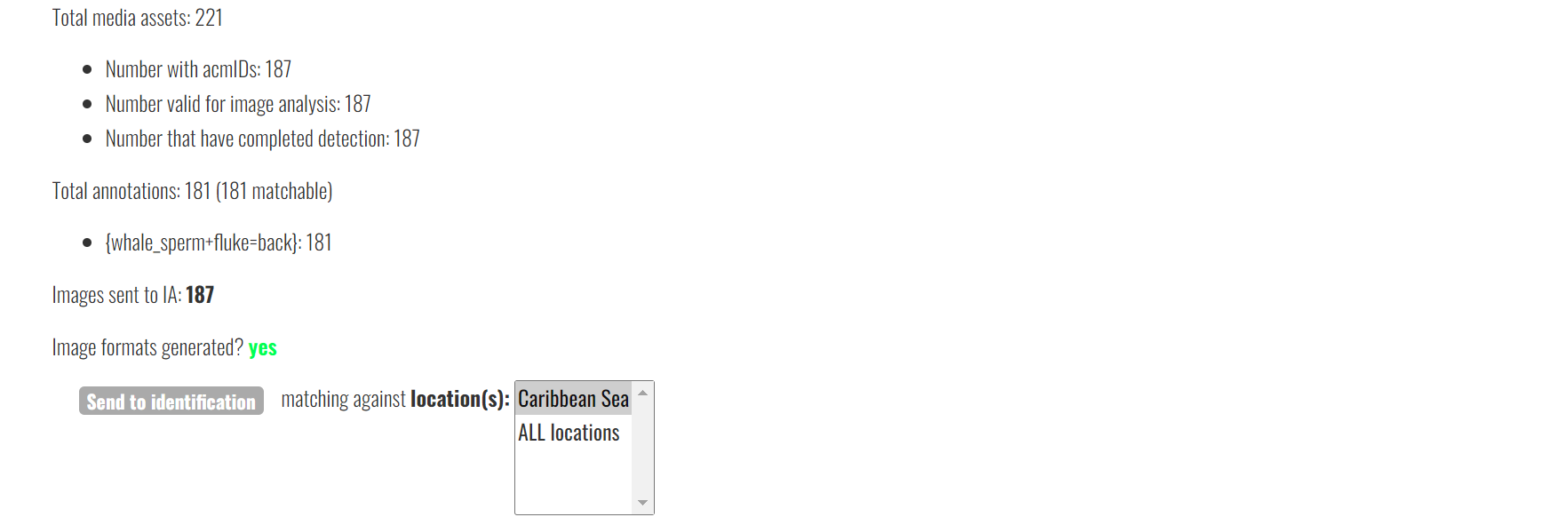
I don’t know if it’s important but I’ve also noticed that every time I send to identification, Flukebook tells me to refresh to track progress but when I do it, the “send to identification” button appears again, even though the identification has started. And another weird thing is when I click on Carribean Sea on the scrolling menu with “All locations” and “Caribbean Sea”, it just appears in grey but it doesn’t properly select it. Since I know it’s not really clear, I joined you a screenshot of what I mean.
Hi @lsimon - I’m the community manager for the African Carnivore Wildbook. We use bulk imports extensively. Each Wildbook is a little different but it’s mostly all very similar functionality. You’ve mentioned a few items, not all of which I can help with but I thought I could share at least what I know from ACW and see if that helps at least a bit.
ID messaging such as “attempting to fetch results” and the hilarious “gave up trying to match” are both actually the same as “waiting for match results” - all mean that the matching processing is still underway for that encounter. 222 images is quite a lot and the Flukebook dataset that it’s matching against is the largest of all the Wildbooks so that will take some time. Added to that is how many other bulk imports are being processed at the same time - all of these factor into how long it takes for a batch to complete IA processing. It’s worth noting that once your batch is underway, the algorithm starts with the first image and moves on from there - not all images will complete consecutively because there may be more of a particular viewpoint to match against for some photos than others, but generally you can check from the top of the list to the bottom to find ones that have completed while others are still being processed.
“Send to identification” button re-appearing after initial send - actually, this is a feature! This allows a user to re-send a bulk import in it’s entirety, through ID again, to pick up any new matches from a more up to date database and to re-generate HotSpotter “inspect” visualizations, which are computationally expensive to generate and store, and so are deleted from the database on a fairly regular basis. It’s why we tell our users not to “send to identification” until a day or so before they’re ready to curate that particular bulk import.
I don’t know why Caribbean Sea isn’t being highlighted when you select it on the bulk import screen but as long as you’ve got it in the location ID column of your metadata spreadsheet, then that’s the region those images will be run against, by default.
I suspect the initial lack of progress on your detection run was nothing other than a very busy detector in Flukebook with likely many other jobs ahead of yours in the queue.
Thanks for the thorough and helpful comment, @ACWadmin1!
@lsimon Thank you for sending me your spreadsheet! It looks good to me. I don’t see anything unusual in it.
Maureen is right about all the above points. Flukebook is currently working through 1600 jobs as of this morning, so long wait times for detection/identification are expected.
Do you have an adblocker on your browser? Sometimes they can make normal site elements behave strangely or not appear at all if they’re too aggressive. Try disabling it on Flukebook to see if that helps.
If you don’t have an adblocker, you can also try clearing your browser’s cache and cookies. That can also resolve issues where a website is not behaving as it normally would.
@ACWadmin1: as far as I understood what you said, it’s quite useless to delete the bulk import if it already passed the “send to detection” step and it’s just stuck at the “send to identification” step because since I have a large bulk import, it will take time anyway. So no matter the message returned by Flukebook, it means that it’s still searching for possible matches. I just wanted to ask you what is a reasonable duration to wait before giving up on this batch (a day, a week, a month), deleting it and retrying again later on. And also, do you think it will maybe worth to delete this large batch and try to divide it in smaller ones to make Flukebook go faster ?
I took a look at the first image, some in the middle and some at the end and they are all indicated the “attempting to fetch results” message so I will wait and see if there is some evolution at some point.
Another question: Is it necessary to let my computer connected to internet during the all identification process (until it’s done) ? Does the fact that my computer could be disconnected by night could have an impact on the overall identification process, like making it slower?
Concerning your second point, I’m not sure if I well understood what you meant: most of the time, it’s better to wait a bit before sending the batch to identification ?
Anyway, thanks a lot for your time and your help!!
@Anastasia: Thank you to have taken a look to my spreadsheet. I’ve tried what you said about disabling my adblocker so I will see if it’s going better afterwards.
Regarding Rebeca and I, we are indeed part of the same organization (ccsngo) but the error about the “send to detection” function was not about the same bulk import (not the same batch of photos, nor species).
That’s helpful context; thanks. Since you’re both using the same userID to submit your imports, it would be helpful if you can link to the specific bulk import you’re having a problem with so I know I’m reviewing the correct upload.
In general, a day for large imports is typical. If it’s already gone through detection but is stuck at identification, I wouldn’t necessarily jump to deleting it and starting over without ruling out other possibilities first.
Nope, detection and identification happen within Flukebook, so your computer’s internet connection doesn’t impact how quickly those complete.
Match results are only cached for about 2 weeks after identification has been run. That means if someone runs ID on an import in January, but doesn’t get around to reviewing matches until July, those matches will have expired and they’ll need to re-run identification again in order to see their match results. Maureen is recommending that if you’re not planning on reviewing your matches on the entire import right away that you can actually hold off on the ID step until you are.
Ok, I’m going to wait until tomorrow morning since I launched the identification process yesterday at 11pm.
I’m taking notes of your recommendations for future bulk imports or for a resubmission of this one in case it still doesn’t work tomorrow.
For the waiting time, for the previous submissions, I indeed had access to the status that was indicating a really long time but for this one (from yesterday), I have nothing more than the “attempting to fetch results” message with no indication of duration after (see the screenshot below).
So I have no idea of the queue or the time left before having my results that’s why, I was concerned about the “send to identification” process not working.
Thanks for the clarification about the internet connection and the detection and identification tasks and the availability of the matching results after identification.
I think it may be a little misunderstanding about the “send to detection” problem. @Rebecca was having it first with her bulk import and then, I was having the same problem with mine later one but I deleted it and when I re-uploaded it, then it was fixed. I was just submitting you my bulk import in case there was maybe something wrong about it that could explain the very long “send to identification” time. I will let Rebecca know that she needs to send you her bulk import spreadsheet for further investigation on her “detection” problem.
Thank you really much for your answers and I will let you know if there is some good news about this identification process working within this week.
We did have some server issues with Flukebook last week that required a few restarts to sort out. A few imports that were stuck before the server restart seemed to work again if they were resubmitted afterward. Sometimes re-importing helps, but because I know it can be time-consuming process, I like to rule out any other issues in the spreadsheet first to reduce the overall troubleshooting steps.
I’m posting your import link here for my own reference so I can find it quicker later: Flukebook | Login
Here’s my suggestion for next steps:
Do you see the empty fields under Match Results by Class? This means that detection could not not find an animal in the image. You’ll first want to manually annotate any encounter that has an empty Match Results by Class field. Once you annotate, you can go back to the encounter page and slick “start match” from the menu on the image, or you can re-run the ID job on all encounters from the bulk import summary.
Since it looks like this was imported yesterday and Flukebook is currently working through 1500 jobs, we may want to give it another day or so to finish detection. Like Maureen said, the various messages in the UI about attempting to fetch results, gave up trying to match, or waiting for match results are typically signs of matching still in progress. I agree that it’s not intuitive and could definitely be improved for all of our sakes.
This thread is awesome, and a lot of these details or in our working protocols but should appear in an FAQ for new users.
One thing I hadnt considered, especially since I know that I and a student with which I work are also adding small batch jobs (also from the Caribbean). Is there anywhere we can check the jobs queue? And just decide to hold off when there are thousands ahead of us? Seems like somehting I should put in as a feature request, maybe for the homepage?
Thanks again for your time and all your advices, it’s been really helpful!
I’ve started to do the annotation manually and I just figured out that some of the pics in my list were in the CRW format and not in JPEG so Flukebook could not read it. I changed the format in JPEG on my computer. For one of my encounter, I upload the new one in JPEG format but the file reference of the old one (in CRW format) still appears and I don’t know how to delete it or if it’s possible to delete it. It appears like this:
Do you think if I do the annotation manually with the new one but keep the old one (not readable by Flukebook) on the encounter page and then, restart the matching process, it will still be a problem for Flukebook ?
Indeed, I’m not sure it’s going to work since the reference in the bulk import spreadsheet will indicate CRW format and not JPEG.
100% agreed. I’m slowly working on this as I learn more about the products and pain points from the folks in Community.
When you re-run a match from the encounter page, it should show you the current job status like in this screenshot. However, I’m spot checking some of @lsimon’s encounters and I’m not seeing this same message appear even though I can see internally that there are 1200 active Flukebook jobs this morning. I’ll find out what’s going on with that, but a feature request for a more easily accessible server status is a great idea.
Oh, that’s interesting! I’ve not seen this before (to be fair, I’ve not worked here very long). CRW is a RAW file format, right? My understanding is that that would be too large of a file for Wildbooks to work with. I checked our docs and it only specifically mentions JPG, BMP and TIFF files, but nothing about RAW formats. This is a great example of what @ShaneGero mentioned of something I need to include in a new user FAQ.
To answer your question, you can delete those from the Metadata section of the encounter page. When you click the edit button, the edit box will have a big, red “Delete Encounter?” button at the bottom. And this is another great example of a question I’m going to add to the FAQ.
Sorry it’s “.CR2” and not CRW but yes basically it’s the same as RAW formats. “.ARW” is another type that Flukebook doesn’t accept if it can help.
Ok thanks for your answer. As I already uploaded all the new ones on each encounter pages, I’m going to try to resubmit and see what happens. And if it still doesn’t work, then I will delete the encounters concerned as you suggested.